CPU Scheduling⚓︎
约 15192 个字 86 行代码 预计阅读时间 77 分钟
Basic Concepts⚓︎
在多道程序设计 (multiprogramming) 中,我们试图高效利用 CPU 的时间,比如当一个进程需要等待时,OS 便收回该进程的 CPU 使用权,并将其交给另一个进程,如此循环往复。这样的调度(scheduling) 操作是 OS 中基本且重要的功能;几乎所有计算机资源在使用前都需要进行调度。
CPU-I/O Burst Cycle⚓︎
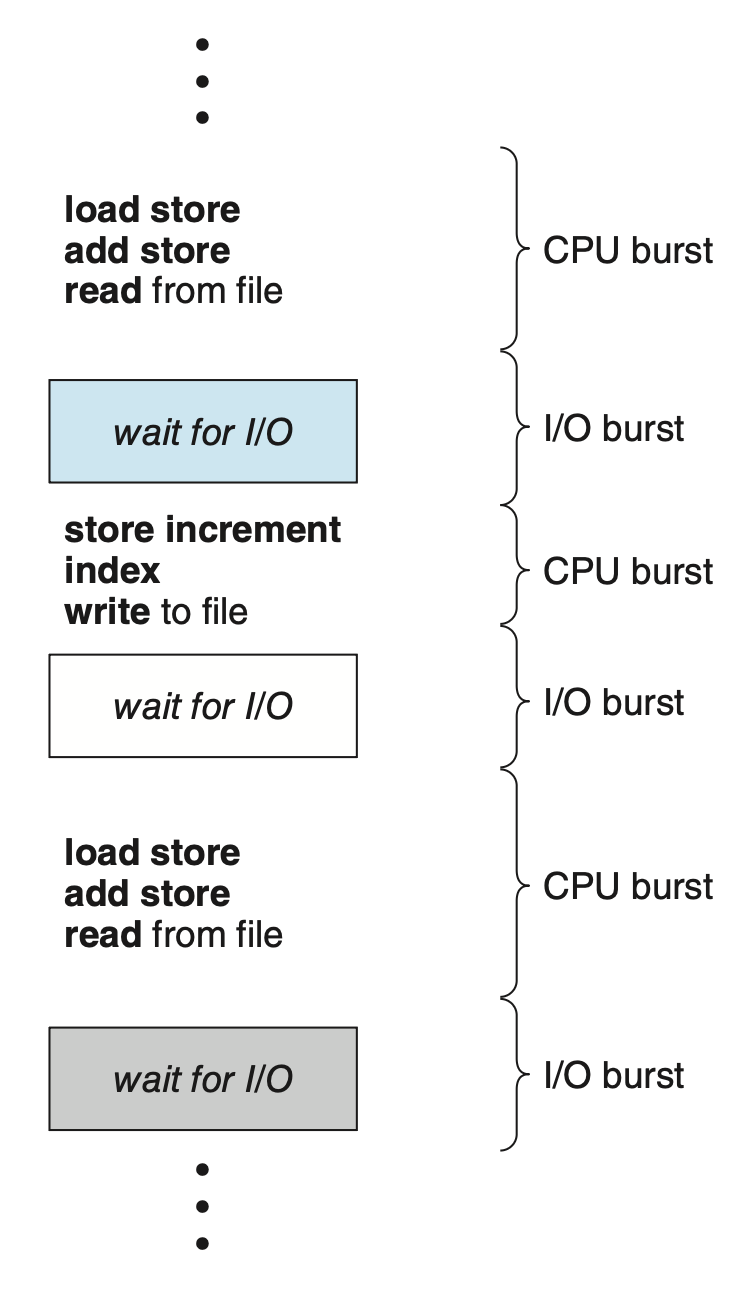
CPU 调度的成功取决于进程的一个特性:进程执行包含了一个 CPU 执行和 I/O 等待的周期(cycle),即进程在这两种状态之间交替进行。
- 进程执行始于一个 CPU 突发周期,随后是一个 I/O 突发周期
- 紧接着又是一个 CPU 突发周期,然后再次是 I/O 突发周期,如此往复
- 最后一个 CPU 突发通过系统请求终止进程的执行
尽管 CPU 突发时间的长度在不同进程和不同计算机之间差异很大,但其频率曲线往往与下图所示相似:
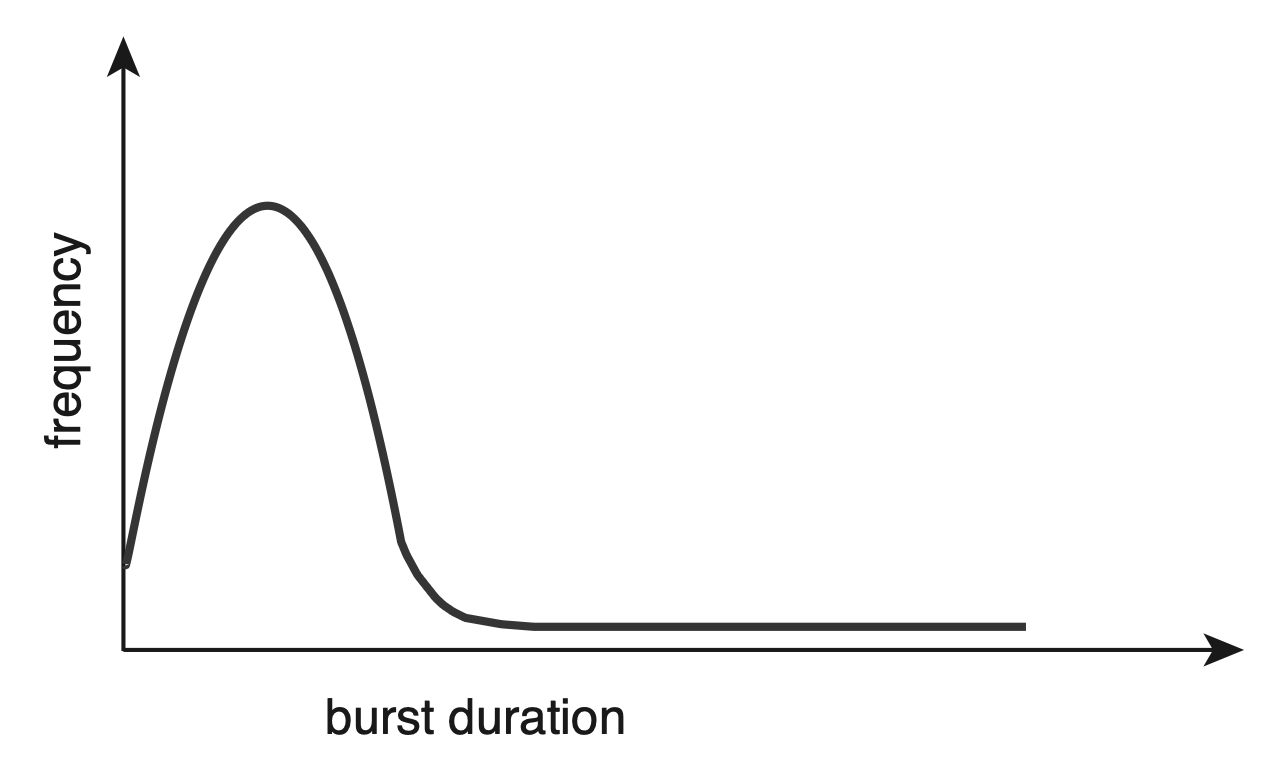
- 该曲线通常以指数型或超指数型的形式呈现,包括了大量的短 CPU 突发和少量的长 CPU 突发
- I/O 密集型程序通常有许多短的 CPU 突发
- 而 CPU 密集型程序则可能只有少数几个长的 CPU 突发
在实现 CPU 调度算法时,上述分布特性至关重要。
CPU Scheduler⚓︎
- 每当 CPU 进入空闲状态时,OS 借助CPU 分派程序(CPU scheduler) 从内存(就绪队列,里面存放有关进程 PCB 的记录)中挑选一个进程,并分配一个 CPU(核心)以执行该进程
- 需要注意的是,就绪队列并不一定是 FIFO 队列,它还可以是优先级队列、树结构,或仅仅是一个无序链表;之后会在“调度算法”一节详细介绍
Preemptive and Nonpreemptive Scheduling⚓︎
CPU 调度决策会在以下几种情况下发生:
- 当进程从运行状态 -> 等待状态
- 当进程从运行状态 -> 就绪状态
- 当进程从等待状态 -> 就绪状态
- 当进程终止时
对于首尾两类情况,在调度方面没有选择的余地:必须从就绪队列中选取一个新进程(如果存在的话)来执行;但对于中间两类情况,我们还是有选择权的。
当仅在首尾两类情况下发生调度时,称这样的调度方案为非抢占式(nonpreemptive) 或协作式(cooperative) 的。否则,即为抢占式(preemptive)。
- 在非抢占式调度下,一旦 CPU 被分配给某个进程,该进程将一直占用 CPU,直到通过终止或切换到等待状态来释放
- 实际上,几乎所有现代 OS 都采用抢占式调度算法
-
然而,当数据在多个进程间共享时,抢占式调度可能导致竞态条件(race condition) 的发生
- 设想两个进程共享数据的情况:当一个进程正在更新数据时被抢占,以便第二个进程得以运行;随后第二个进程尝试读取这些处于不一致状态的数据
- 这一问题将在下一讲介绍进程同步时详细探讨
-
抢占机制影响着 OS 内核的设计
- 在执行系统调用期间,内核可能正忙于执行代表某个进程的活动,这类活动或许涉及修改关键的内核数据;若在此更改过程中进程被抢占,而内核又需要读取或修改同一结构时,结果就是一团糟
- OS 内核可设计为非抢占式或抢占式两种类型
- 非抢占式内核会等待系统调用完成,或在等待 I/O 操作完成导致进程阻塞后,才进行上下文切换
- “等待 I/O 操作完成导致进程阻塞引起的上下文交换”是一种重叠(overlap) 操作,能提高 CPU 利用率
- 这种方案确保了内核结构的简洁性,因为在内核数据结构处于不一致状态时,内核不会抢占进程
- 然而对于必须确保任务在指定时限内完成的实时计算而言,这种内核执行模式表现欠佳
- 而抢占式内核则需要互斥锁(mutex locks) 等机制来防止访问共享内核数据结构时的竞态条件问题
- 目前大多数现代 OS 在内核模式下运行时已完全实现抢先式处理能力
- 非抢占式内核会等待系统调用完成,或在等待 I/O 操作完成导致进程阻塞后,才进行上下文切换
-
由于中断可能随时发生,且内核不能忽略它们,因此必须保护受中断影响的代码段,防止被同时使用
- OS 几乎在任何时候都需要接受中断,否则输入可能会丢失,或输出被覆盖
- 为了避免代码段被多个进程并发访问,它们在入口处禁用中断,并在出口处重新启用中断
- 但禁用中断的代码段并不常见,且通常只包含少量指令
Dispatcher⚓︎
CPU 调度功能中的另一个组成部分是分派程序(dispatcher),它是将 CPU 核心的控制权交给由 CPU 调度程序选定进程的模块,其功能包括以下几个方面:
- 从一个进程切换到另一个进程的上下文
- 切换到用户模式
- 跳转到用户程序中的适当位置,以恢复该程序的执行
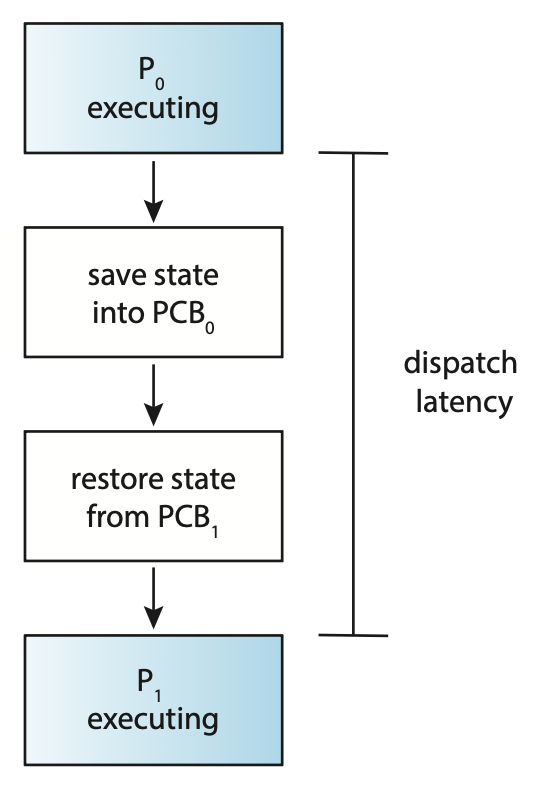
分派程序应尽可能快速,因为每次上下文切换时都会调用它。分派程序停止一个进程,并启动另一个进程所需的时间被称为分派延迟(dispatch latency),如右图所示:
在 Linux 系统中,可用 vmstat 命令来获取上下文切换的次数,以下是该命令的输出:

- 第一行显示自系统启动以来,每秒的平均上下文切换次数
- 接下来的两行则分别给出了两个连续 1 秒间隔内的上下文切换次数
另外也可以利用 /proc 文件系统来确定特定进程的上下文切换次数。例如,查看文件 /proc/2166/status 的内容将会列出进程 ID 为 2166 的各项统计信息。命令 cat /proc/2166/status 的部分输出如下:
此输出显示了该进程生命周期内的上下文切换次数。这里要注意自愿(voluntary) 与非自愿(nonvoluntary) 上下文切换之间的区别:
- 当进程因所需资源当前不可用而放弃 CPU 控制权时,发生的是自愿上下文切换
- 而非自愿上下文切换则发生在 CPU 被强制从进程中夺走的情况下,比如其时间片已用完,或被更高优先级的进程抢占
Scheduling Criteria⚓︎
不同的 CPU 调度算法具有各自的特点,选择特定的算法可能会对某一类进程更为有利,因此在选用何种算法时就得必须考量各种算法的特性。已有多种用于比较 CPU 调度算法的评判标准,包括了:
-
CPU 利用率(CPU utilization):
- 我们希望尽可能让 CPU 保持忙碌状态
- 理论上,CPU 利用率可以在 0% 到 100% 之间变化
- 而在实际系统中,它通常应在 40%(对于负载较轻的系统)至 90%(对于负载较重的系统)的范围内
-
吞吐量(throughput):单位时间内完成的进程数量
-
周转时间(turnaround time):一个进程从提交(到达)到完成所经历的时间间隔,包括了该进程在就绪队列中等待,在 CPU 上执行,以及进行 I/O 操作所花费时间的总和
- 它是一个性能指标
-
等待时间(waiting time):在就绪队列中所有等待时段的总和
- CPU 调度算法并不影响进程执行或进行 I/O 操作的时间总量,它仅影响进程在就绪队列中等待的时间量
-
响应时间(response time):从请求提交(到达)到首次产生响应的时间
- 常用于交互式系统中
- 有时响应时间也指从请求到达到系统首次调度的时间,和上述定义略有区别
- 它是一个公平性(fairness) 指标,即在小时间尺度上,将 CPU 均匀分配给活跃进程
理想情况下,我们希望最大化 CPU 利用率和吞吐量,同时最小化周转时间、等待时间和响应时间。
- 在多数场景下,我们优化的是平均指标
-
然而在某些特定情况下,我们更倾向于优化最小值或最大值而非平均值
- 例如,为了确保所有用户都能获得良好的服务体验,我们可能希望将最大响应时间降至最低
-
对于交互式系统,减小响应时间的方差(variance) 比降低平均响应时间更为关键
- 一个响应时间合理且可预测的系统,即便其平均速度不是最快但表现稳定,通常被认为优于那些平均速度快但波动大的系统
- 不过目前针对减少方差进行优化的 CPU 调度算法研究尚不充分
Scheduling Algorithms⚓︎
接下来介绍多种不同的 CPU 调度算法。需要注意的是,我们目前仅考虑单个可用处理核心的情况,即一个 CPU 只能在某一时间段内运行一个进程的情况,而关于多处理器系统中的 CPU 调度问题会放到后面讨论。
First-Come, First-Served Scheduling⚓︎
最简单的 CPU 调度算法就是先来先服务(first-come first-served, FCFS) 调度算法。
- 请求 CPU 的首个进程会被优先分配 CPU
- 通过一个先进先出(FIFO)队列可以轻松实现 FCFS 策略
- 当一个进程进入就绪队列时,其 PCB 会被链接该队列的尾部
- 而空闲的 CPU 会被分配给队列头部的进程,随后从队列中移除该进程
- 编写和理解 FCFS 调度的代码非常简单
- 但缺点是平均等待时间通常较长
例子
假如以下一组进程在时刻 0 到达,它们的 CPU 突发长度(单位:ms)如下所示:

若这些进程的到达顺序为 \(P_1, P_2, P_3\),那么可以用甘特图(Gantt chart) 表示为:

不难得出,\(P_1, P_2, P_3\) 的等待时间分别为 0ms,24ms 和 27ms,因此平均等待时间为 17ms。然而,若到达顺序为 \(P_2, P_3, P_1\),用甘特图表示为:

读者可自行计算,此时平均等待时间变为 3ms,降低幅度相当之大啊!因此在 FCFS 策略下,平均等待时间通常不是最短的;并且如果进程的 CPU 执行时间差异很大时,这一时间可能会(随进程到达顺序)有显著变化。
假设有一个 CPU 密集型进程和多个 I/O 密集型进程。随着这些进程在系统中流转,可能会出现以下情形:
- CPU 密集型进程会获取并占用 CPU,在此期间所有其他进程将完成它们的 I/O 操作并进入就绪队列,并等待使用 CPU,此时 I/O 设备处于闲置状态
- 之后,CPU 密集型进程完成了其 CPU 突发时间,并转移到某个 I/O 设备上;此时那些具有较短 CPU 突发的 I/O 密集型进程迅速执行完毕后返回至各自的 I/O 队列,此时 CPU 便空闲下来
- 随后那个 CPU 密集型进程又会回到就绪队列并使用 CPU;所有的 I/O 处理进程又在就绪队列等待那个进程完成
这就是所谓的护航效应(convoy effect):众多相对较短的资源消费者(进程)排在一个占用资源很多的消费者的后面,这导致 CPU 和设备利用率很低。
注意 FCFS 调度算法是非抢占式的,所以一旦 CPU 被分配给某个进程,该进程就会一直占用 CPU,直到其释放。因此对于交互式系统而言,FCFS 算法的表现非常烂。
Shortest-Job-First Scheduling⚓︎
第二种要介绍的算法是短作业优先(shortest-job-first, SJF) 调度算法。
-
该算法将每个进程的下一个 CPU 突发周期长度与其关联起来
- 因此这种调度方法更准确的名称应为“最短下一 CPU 突发周期 (shortest-next-CPU-burst)”算法
- 之所以使用 SJF 这一术语,是因为大家都这么说 ...
-
当 CPU 空闲时,它会分配给下一个 CPU 执行周期最短的进程
- 如果两个进程的下一个 CPU 执行周期相同,则采用 FCFS 调度来决定顺序
例子
考虑下面一组进程,并给出对应 CPU 突发长度(单位:ms

以下甘特图是使用 SJF 调度算法后得到的结果:

不难计算出平均等待时间为 7ms。相对地,用 FCFS 调度算法得到的平均等待时间位 10.25ms。
SJF 调度算法被证明是最优的,因为它能为给定的一组进程提供最小的平均等待时间。将一个短进程移到长进程之前,会减少短进程的等待时间,其减少量大于长进程等待时间的增加量,因此平均等待时间得以降低。
尽管 SJF 算法是最优的,但实际上无法精确实施,因为无法得知下一个 CPU 突发的长度。针对这一问题,一种解决思路是尝试近似表示 SJF 调度。通常认为,下一次的 CPU 突发长度会与前一次的类似,于是我们能够选择预计处理时间最短的那个进程来执行了。
更准确的说法是,下一个 CPU 突发的预测通常基于先前 CPU 突发长度的指数平均。设 \(t_n\) 为第 \(n\) 个 CPU 的突发长度,\(\tau_{n+1}\) 为下一个 CPU 突发的预测值。对于 \(0 \le \alpha \le 1\),预测值的定义为: $$ \tau_{n+1} = \alpha t_n + (1 - \alpha) \tau_n $$
其中
- \(t_n\) 的值包含最近信息
-
\(\tau_n\) 则存储了过去的历史记录
- 初始值 \(\tau_0\) 可以定义为一个常数或系统的整体平均值
-
\(\alpha\) 控制着近期与过去历史在预测中的相对权重
- 一般取 \(\alpha = \dfrac{1}{2}\),这样近期历史和过去历史就被赋予了相同的权重
下图展示了下一次 CPU 突发的预测结果(\(\alpha = \dfrac{1}{2}, \tau_0 = 10\)
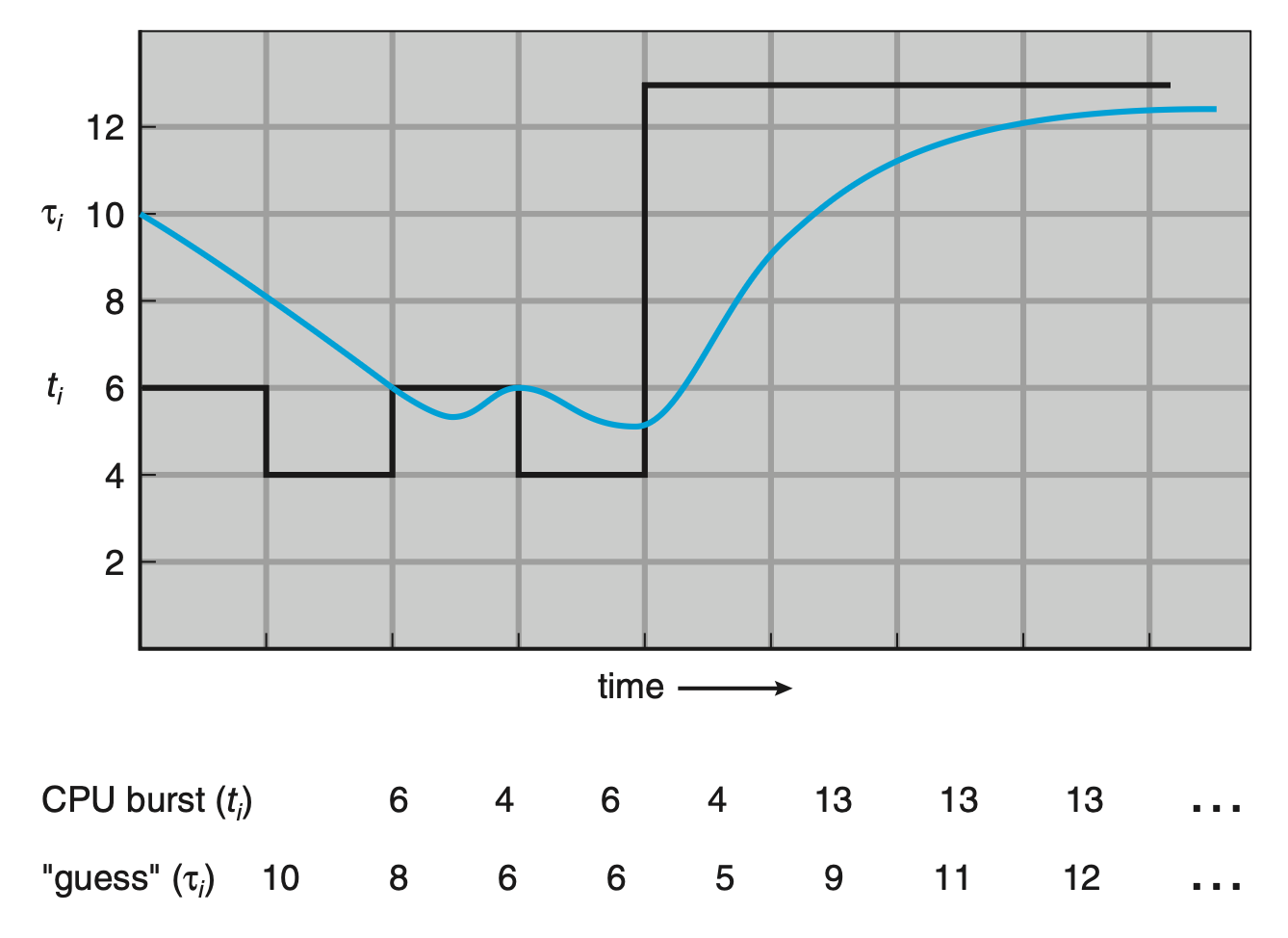
要理解指数平均,我们可通过替换 \(\tau_n\) 来展开 \(\tau_{n+1}\) 的公式,得到: $$ \tau_{n+1} = \alpha t_n + (1 - \alpha)\alpha t_{n-1} + \cdots + (1 - \alpha)^j \alpha t_{n-j} + \cdots + (1 - \alpha)^{n+1}\tau_0 $$
由于 \(\alpha < 1\),因此 \(1 - \alpha < 1\),且每一个连续项都比它之前的项有更小的权重。
SJF 算法可以是抢占式,也可以是非抢占式的。当新到达就绪队列的进程的下一个 CPU 突发可能比当前正在执行的进程剩余时间更短时,
- 抢占式 SJF 算法会中断当前执行中的进程
- 有时也被称为最短剩余时间优先(short-remaining-time-first) 调度
- 而非抢占式 SJF 算法则允许当前运行的进程完成其 CPU 突发
例子
考虑下面一组进程,并给出对应 CPU 突发长度(单位:ms
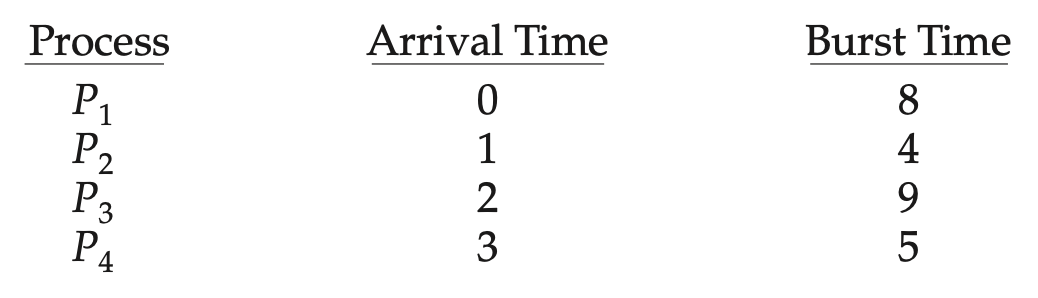
以下甘特图是使用抢占式 SJF 调度算法后得到的结果:

- 由于 \(P_1\) 剩余的执行时间大于 \(P_2\) 所需时间,因此 \(P_1\) 的 CPU 被抢占给 \(P_2\);\(P_4\) 也是同理
- 不难计算出平均等待时间为 6.5ms;相对地,非抢占式 SJF 调度的平均等待时间为 7.75ms
Round-Robin Scheduling⚓︎
- 轮询(round-robin, RR) 调度算法类似 FCFS 调度,但引入了抢占机制,使系统能够在进程间切换
- 该算法定义了一个小的时间单位,称为时间片(time quantum/slice),其长度通常为 10 到 100ms
- CPU 调度器为每个进程分配最多 1 个时间片的时间间隔
- 之所以说 RR 调度算法是抢占式的,是因为不会为任何进程连续分配超过 1 个的时间片(除非它是目前唯一可运行的进程
) ,超过 1 个时间片还没执行完毕的进程将被抢占,并重新放入至就绪队列中 - 时间片大小必须是定时器中断周期的倍数
- 就绪队列被视为一个环形队列
为了实现 RR 调度算法,需再次将就绪队列视为一个 FIFO 进程队列:
- 新进程会被添加到就绪队列的尾部
- CPU 调度器从就绪队列中选取首个进程,设置一个在 1 个时间片后中断的定时器,并分派该进程
之后会发生两种情况之一。
- 进程的 CPU 突发周期 <= 1 个时间片:进程会主动释放 CPU,随后调度器将选择就绪队列中的下一个进程
- 进程的 CPU 突发周期 > 1 个时间片:
- 定时器将会触发,并向 OS 发出中断信号
- 此时执行上下文切换,并将该进程移至就绪队列的末尾
- 接着 CPU 调度器会选择就绪队列中的下一个进程继续执行
不幸的是,RR 策略下的平均等待时间通常很长。
例子
考虑下面一组进程(到达时刻均为 0

以下甘特图是使用时间片 = 4ms 的 RR 调度算法后得到的结果:

- 由于 \(P_1\) 的突发长度远大于时间片,而 \(P_2, P_3\) 的突发长度则小于 1 个时间片,因此等执行完 1 个时间片的 \(P_1\),以及完整的 \(P_2, P_3\) 后,剩下的 CPU 时间都是给 \(P_1\) 的(包括了 5 个时间片)
- \(P_1\) 等待事件为 6ms,而平局等待时间为 5.66ms
如果就绪队列中有 \(n\) 个进程,且时间片为 \(q\),那么每个进程最多以不超过 \(q\) 个时间单位的时间块获得 CPU 时间的 \(\dfrac{1}{n}\), 并且每个进程等待下一个时间片的时间不会超过 \((n - 1) \times q\) 个时间单位。
RR 算法的性能在很大程度上取决于时间片的大小:
- 若时间片非常大,则 RR 策略 = FCFS 策略,那么响应性就很差了
-
若时间片非常小,则会引入大量的上下文切换成本,如下图所示:
- 上下文切换成本包括:保存和恢复寄存器值、处理 CPU 高速缓存、TLB、分支预测器等硬件的状态
- 所以我们希望时间片相对于上下文切换时间要足够大;而实际上大多数现代 OS 的时间片范围在 10-100ms 之间,而一次上下文切换所需的时间通常 < 10μs,因此无需担心这个问题
以周转时间作为指标,RR 算法是已经介绍的三种算法当中最烂的,因为使用 RR 算法后,每个进程的完成时间都会被往后推,显然会增大周转时间。
事实上,所有像 RR 这样注重公平性的算法在周转时间上表现都很糟。这里面体现了一种权衡(trade-off):
- 要是允许不公平,那就可以让最短的进程先完成运行,代价是损害了响应时间
- 要是注重公平性,响应时间减少了,但代价是损害了周转时间
所以响应时间和周转时间是一种“鱼和熊掌不可兼得”的关系。
Priority Scheduling⚓︎
前面介绍的 SJF 算法是优先级调度(priority-scheduling) 算法的一个特例(优先级 = 下一次 CPU 突发的倒数
- 每个进程关联一个优先级,且 CPU 会被分配给优先级最高的进程
- 相等优先级的进程以 FCFS 顺序调度
- 一般用一组范围固定的数字表示优先级
- 但对于 0 是最高优先级还是最低优先级,目前仍没有达成一致意见,以后我们就假定用小数字表示高优先级
例子
考虑下面一组进程(到达时刻均为 0

以下甘特图是使用优先级调度算法后得到的结果:

平均等待时间为 8.2ms。
优先级的定义可分为来自内部和来自外部。
- 内部优先级:使用某些可度量的量来计算进程的优先级
- 例如:时间限制、内存需求、打开文件的数量、平均 I/O 突发与平均 CPU 突发的比率等
- 外部优先级:由 OS 外部的标准设定的
- 比如进程的重要性、支付计算机使用的资金类型和金额、资助工作的部门、其他常常带有政治色彩的因素等
优先级调度可以是抢占式或非抢占式的。若新到达进程的优先级高于当前运行进程的优先级,
- 抢占式算法将剥夺当前进程的 CPU 使用权
- 而非抢占式算法则仅将新进程置于就绪队列的首位
优先级调度算法的一个主要问题是无限期阻塞(indefinite blocking),或称饥饿(starvation)。
- 一个准备就绪但等待 CPU 的进程可被视为被阻塞状态 (blocked)
- 优先级调度算法可能导致某些低优先级进程无期限地等待,比如在负载较重的计算机系统中,持续不断的高优先级进程流可能会阻止低优先级进程获得 CPU 使用权
- 此时通常会出现两种情况之一:
- 要么该进程最终得以运行(比如在某一时刻系统负载终于减轻时)
- 要么计算机系统最终崩溃,并丢失所有未完成的低优先级进程
解决该问题的一个方法是老化(aging),即逐渐提高在系统中长时间等待的进程的优先级。
- 假如优先级的范围是从 127(最低)到 0(最高
) ,我们可以定期(比如每秒)将等待中进程的优先级提高 1 - 最终,即使初始优先级为 127 的进程也会拥有系统中的最高优先级并得到执行
另一种方案是将 RR 调度与优先级调度相结合:系统仍然执行最高优先级的进程,但对相同优先级的进程采用 RR 调度的方式执行。
例子
考虑下面一组进程(到达时刻均为 0

以下甘特图是使用优先级调度 + RR 调度(时间片 = 2ms)算法后得到的结果:

- 由于 \(P_2, P_3\) 优先级相同,因此它们以轮询方式交替执行;但 \(P_2\) 会率先完成,所以剩下的时间都交给 \(P_3\) 了
- \(P_1, P_5\) 同上
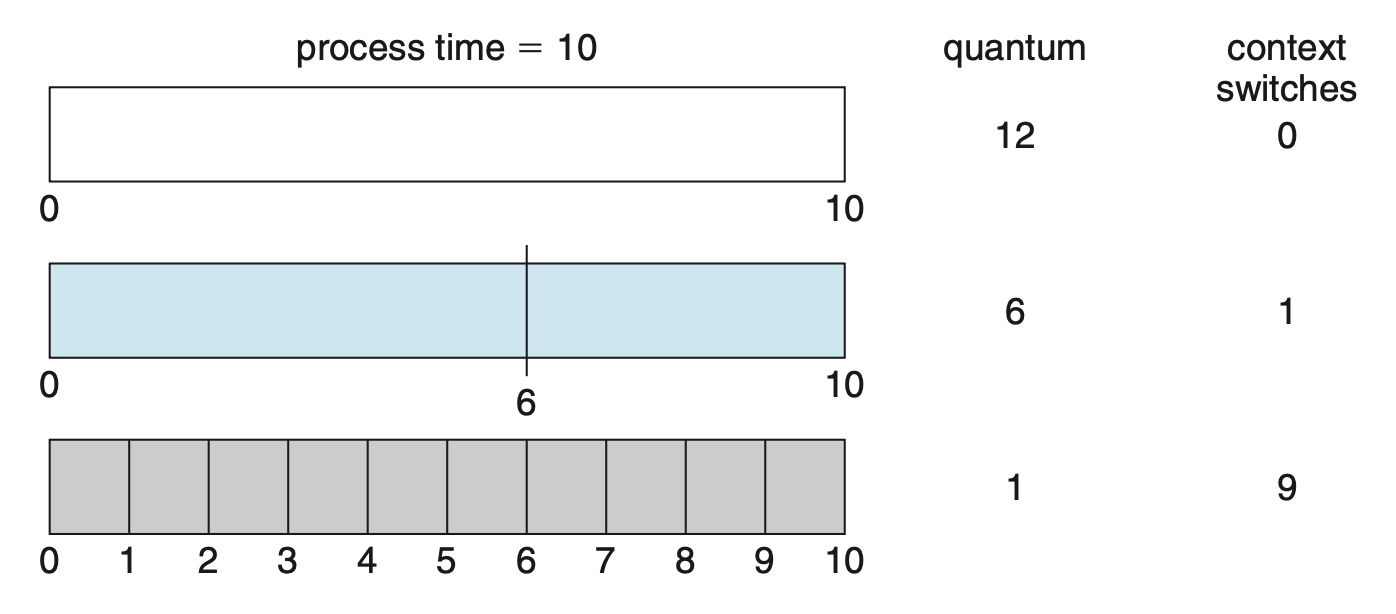
Multilevel Queue Scheduling⚓︎
在优先级 + RR 调度算法中,所有进程都放置在单个队列中,因此需要 \(O(n)\) 的搜索来找到最高优先级的进程。实际上,为不同优先级设置单独的队列通常更容易,此时只需在最高优先级的队列中采用优先级调度算法安排进程。这种方法称为多级队列(multilevel queue),如右图所示。
该方法仍然可以结合 RR 调度实现:若最高优先级队列中有多个进程,它们将按 RR 顺序执行。
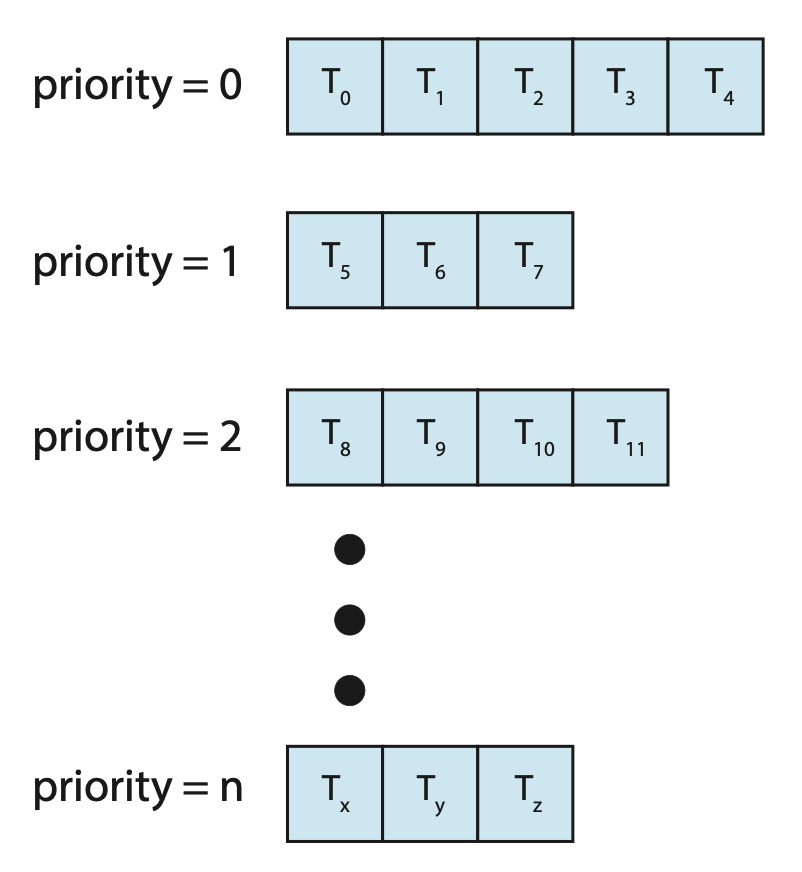
多级队列调度算法也可根据进程类型将进程划分到多个独立的队列中,其中每个队列对低优先级队列具有绝对优先权,如下图所示:
一种常见的划分方式是将前台(foreground)(交互式(interactive))进程与后台(background)(批处理(batch))进程分开。
- 因为这两类进程对响应时间的要求不同,所以可能需要不同的调度策略
- 前台进程可能拥有比后台进程更高的优先级(外部定义)
- 可以为前台和后台进程分别设置队列,且每个队列可各自采用不同的调度算法,比如前台队列用 RR 调度,而后台队列用 FCFS 调度
此外,队列之间必须进行调度,一般通过固定优先级的抢占式调度来实现。
另一种可能是在队列之间进行时间切片:每个队列都获得一定比例的 CPU 时间,然后可以将其调度给各种进程。比如在前台 - 后台队列示例中,前台队列可以为其进程分配 80% 的 CPU 时间进行 RR 调度,而后台队列则接收 20% 的 CPU 时间,以 FCFS 方式分配给其进程。
Multilevel Feedback Queue Scheduling⚓︎
通常在采用多级队列调度算法时,一旦进入系统,进程就会被永久地分配到某个队列中。这种设置的优点是调度开销小,但缺乏灵活性。
相比之下,多级反馈队列(multilevel feedback queue) 调度算法允许进程在不同队列间移动。
- 其核心思想是根据进程 CPU 执行时间的特点进行分类
- 若某进程占用过多 CPU 时间,则会被移至较低优先级的队列中
- 这样一来,通常以短 CPU 执行为特征的 I/O 密集型及交互式进程便能留在较高优先级的队列里
- 此外,在低优先级队列中等待过久的进程也可能被提升至高优先级队列,这种老化机制有效防止了饥饿现象的发生
例子
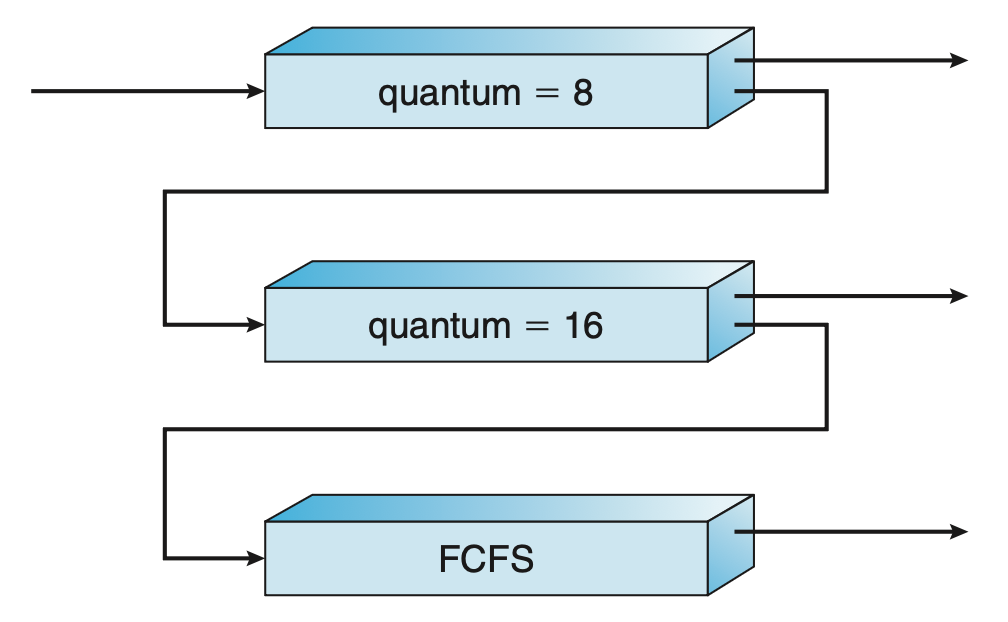
考虑一个具有三个队列的多级反馈队列调度器,编号从 0 到 2。
- 调度器首先执行队列 0 中的所有进程,只有当队列 0 为空时,它才会执行队列 1 中的进程;同样地,只有在队列 0 和 1 都为空的情况下,才会执行队列 2 中的进程
- 到达队列 1 的进程会抢占正在执行的来自队列 2 的进程,而到达队列 0 的进程则会抢占正在执行的来自队列 1 的进程
- 一个新进程会先进入队列 0
- 队列 0 中的进程被分配 8ms 的时间片,若在此时间内未能完成,则将其移至队列 1 的末尾
- 如果队列 0 为空,则从队列 1 头部取出一个进程并给予 16ms 的时间片;若该进程仍未完成,它将被抢占并放入队列 2 中
- 队列 2 中的进程按 FCFS 原则运行,但仅当队列 0 和 1 均为空时才执行
- 为防止饥饿现象发生,长时间在低优先级队列等待的进程可能会逐步迁移至高优先级队列中
总的来说,多级反馈队列调度器由以下参数定义:
- 队列数
- 每个队列的调度算法
- 用于确定何时将进程升级至更高优先级队列的方法
- 用于确定何时将进程降级至更低优先级队列的方法
- 用于确定当进程需要服务时,要进入哪个队列的方法
多级反馈队列调度器是最通用的 CPU 调度算法,但这也让它成为最为复杂的算法。
Thread Scheduling⚓︎
本节将探讨用户级和内核级线程的调度问题,并提供针对 Pthreads 调度的具体示例。
Contention Scope⚓︎
用户级线程与内核级线程之间的一个区别在于它们的调度方式。
- 在实现多对一和多对多模型的系统中,线程库将用户级线程调度到可用的轻量级进程(LWP)上运行,这种机制被称为进程竞争范围(process-contention scope, PCS),因为 CPU 的竞争发生在属于同一进程的线程之间。
- 通常,PCS 是根据优先级进行的:调度器选择具有最高优先级的可运行线程来运行。该优先级由程序员设置,线程库不会调整,尽管某些线程库可能允许程序员更改线程的优先级。
- 需要注意的是,PCS 通常会抢占当前运行的线程以运行更高优先级的线程,但对于同等优先级的线程之间,没有时间片分配的保证。
- 为了决定哪个内核级线程被调度至 CPU,内核采用系统竞争范围(system-contention scope, SCS)。在此调度下,系统内所有线程都会参与对 CPU 的竞争。采用一对一模型的系统仅使用 SCS 来调度线程。
Pthread Scheduling⚓︎
Pthreads 定义了以下竞争范围值:
PTHREAD_SCOPE_PROCESS:使用 PCS 调度线程PTHREAD_SCOPE_SYSTEM:使用 SCS 调度线程
在多对多模型的系统中,
PTHREAD_SCOPE_PROCESS策略将用户级线程调度到可用的 LWP 上;其数量由线程库维护,可能使用调度激活PTHREAD_SCOPE_SYSTEM调度策略将为每个用户级线程创建和绑定一个 LWP,有效地使用一对一策略映射线程
Pthread IPC(进程间通信)提供了两个用于设置和获取竞争范围策略的函数:
pthread_attr_setscope(pthread_attr_t *attr, int scope)pthread_attr_getscope(pthread_attr_t *attr, int *scope)
这两个函数的第一个参数都包含一个指向线程属性集的指针。而对于第二个参数
pthread_attr_setscope()传入的是PTHREAD_SCOPE_SYSTEM或PTHREAD_SCOPE_PROCESS值,用以指示竞争范围pthread_attr_getscope()传入的是一个指向整型值的指针,该值被设置为当前竞争范围的值
若发生错误,这些函数均会返回非零值。
例子
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
int main(int argc, char *argv[]) {
int i, scope;
pthread_t tid[NUM THREADS];
pthread_attr_t attr;
/* get the default attributes */
pthread_attr_init(&attr);
/* first inquire on the current scope */
if (pthread_attr_getscope(&attr, &scope) != 0)
fprintf(stderr, "Unable to get scheduling scope\n");
else {
if (scope == PTHREAD_SCOPE_PROCESS)
printf("PTHREAD_SCOPE_PROCESS");
else if (scope == PTHREAD_SCOPE_SYSTEM)
printf("PTHREAD_SCOPE_SYSTEM");
else
fprintf(stderr, "Illegal scope value.∖n");
}
/* set the scheduling algorithm to PCS or SCS */
pthread_attr_setscope(&attr, PTHREAD SCOPE SYSTEM);
/* create the threads */
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i], &attr, runner, NULL);
/* now join on each thread */
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param) {
/* do some work ... */
pthread_exit(0);
}
Multi-Processor Scheduling⚓︎
目前的讨论主要集中在如何在单核处理器系统上调度 CPU 的问题。当系统拥有多个 CPU 时,便可以实现负载共享(load sharing),允许多个线程并行运行,但与此同时调度问题也相应地变得更加复杂。大量实践表明,此时不存在一种最优的调度算法。
传统上
- 多核心 CPU
- 多线程核心
- NUMA 系统
- 异构多处理(heterogeneous multiprocessing)
接下来,我们先来关注功能上相同的,即同构的(homogeneous) 处理器系统,这意味着可以使用任意可用的 CPU 来运行队列中的任何进程。最后再来探讨当处理器能力各不相同的系统的情况。
Approaches to Multiple-Processor Scheduling⚓︎
在多处理器系统中,一种 CPU 调度方法是将所有调度决策、I/O 处理及其他系统活动交由单一处理器——主服务器来处理。其余处理器仅执行用户代码。这种非对称多处理(asymmetric multiprocessing) 方式较为简单,因为只有一个核心访问系统数据结构,从而减少了对数据共享的需求。然而,此方法的弊端在于主服务器可能成为瓶颈,导致整体系统性能下降。
支持多处理器的标准做法是对称多处理(symmetric multiprocessing, SMP),其中每个处理器可自行进行调度 (self-scheduling)。此时有两种可能的组织可被调度线程的策略:
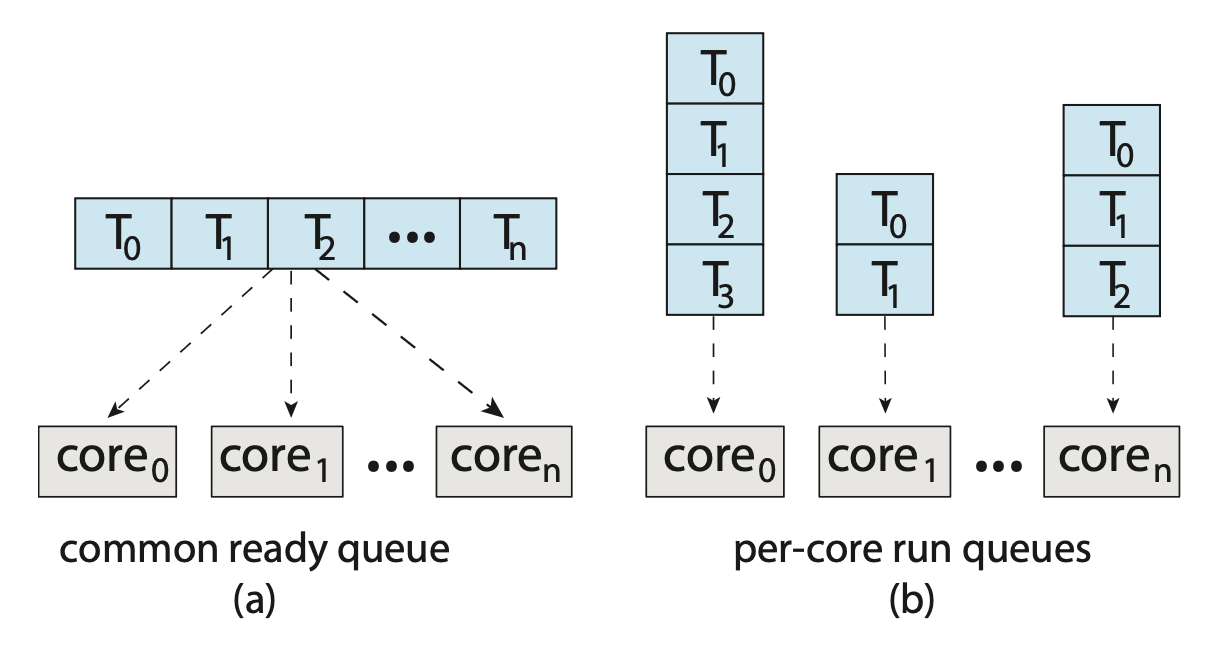
- 所有线程位于一个公共的就绪队列(左图)
- 公共就绪队列上可能存在竞态条件,因此必须确保两个独立的处理器不会同时调度同一个线程,并且线程不会从队列中丢失
- 可以使用某种形式的锁来保护公共就绪队列,但这样做竞争就来到了锁上面,因为所有对队列的访问都需要锁的所有权,因而访问共享队列可能成为性能瓶颈
- 每个处理器有自己的私有线程队列(右图)
- 不会遇到与共享运行队列相关的性能问题,因此这是支持 SMP 的系统中最常见的方法。
- 这种设计能更有效地使用高速缓存
- 最大的问题是工作量的不同,不过可通过均衡算法,在所有处理器之间平衡负载
Multicore Processors⚓︎
现今大多数计算机硬件将多个计算核心集成在同一块物理芯片上,形成了多核处理器(multicore processor)。每个核心维护其自身的架构状态,因此对 OS 而言,它们表现为独立的逻辑 CPU。采用多核处理器的 SMP 系统比每个 CPU 拥有独立物理芯片的系统速度更快且能耗更低。
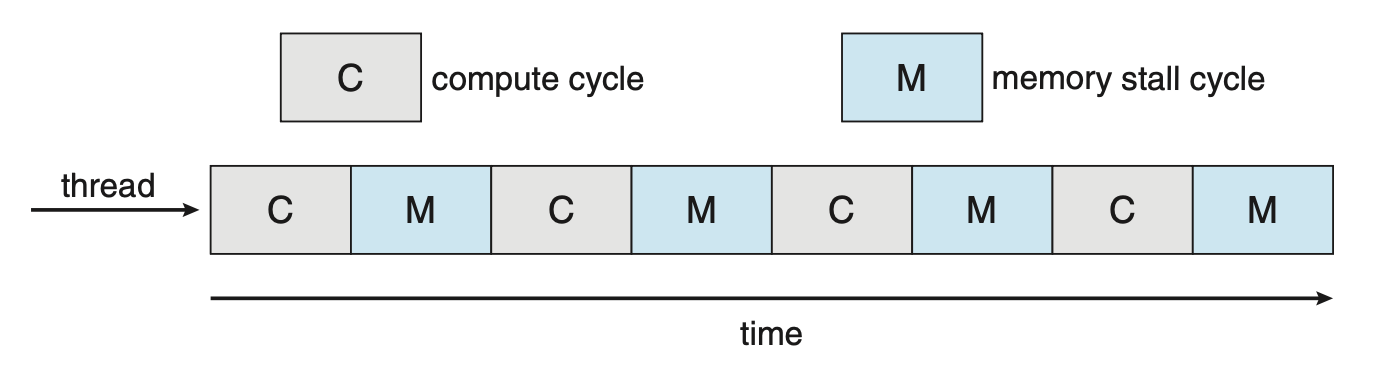
多核处理器可能会使调度问题复杂化。当处理器访问内存时,会花费大量时间等待数据准备就绪,这种现象被称为内存停顿(memory stall),如下图所示。原因是现代处理器的运算速度远超内存速度;另外高速缓存失效(catch miss)(即访问的数据不在高速缓存中)也可能导致内存停顿的发生。
针对这一情况,近期的许多硬件设计采用了多线程处理核心,每个核心分配两个(或更多)硬件线程(hardware thread)。这样一来,若某个硬件线程在等待内存时停顿,核心便能切换至另一线程。下图展示了一个双线程处理核心的示例,其中线程 0 与线程 1 的执行是交错进行的。
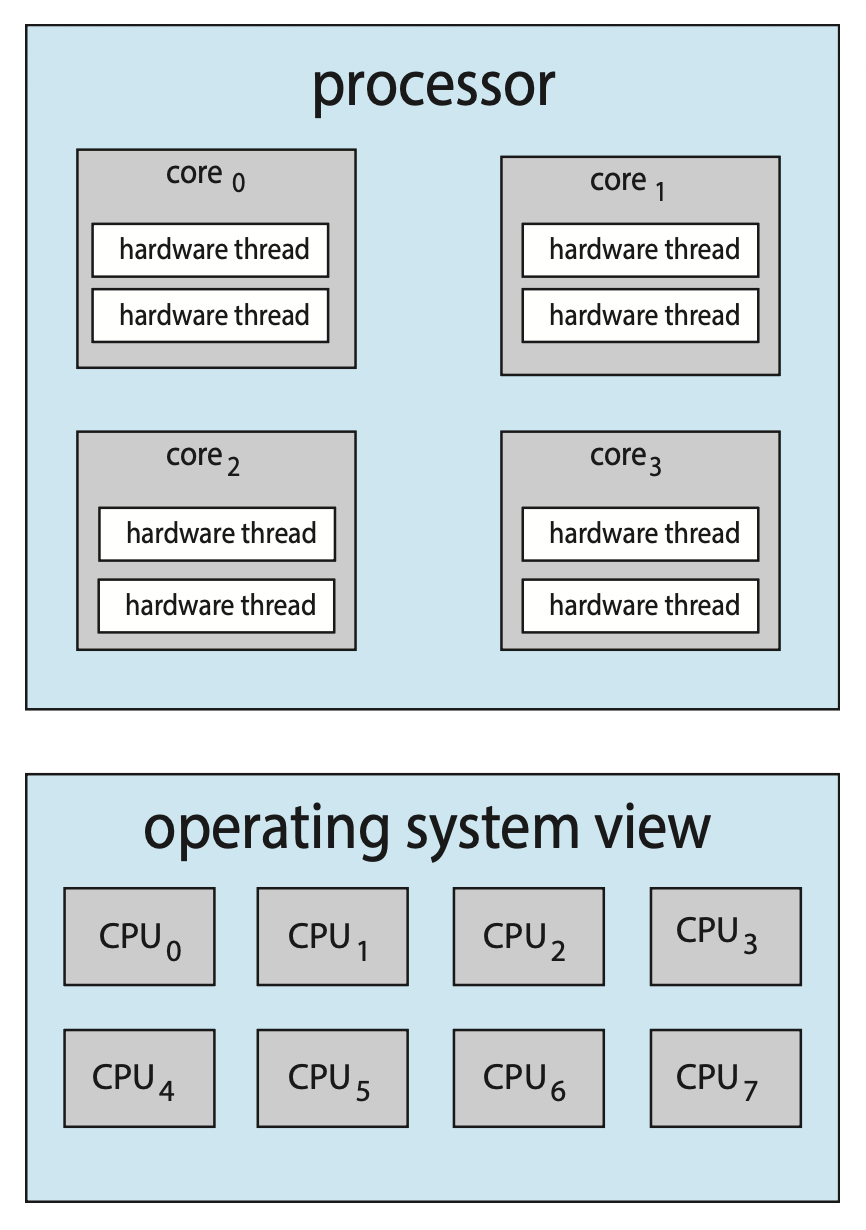
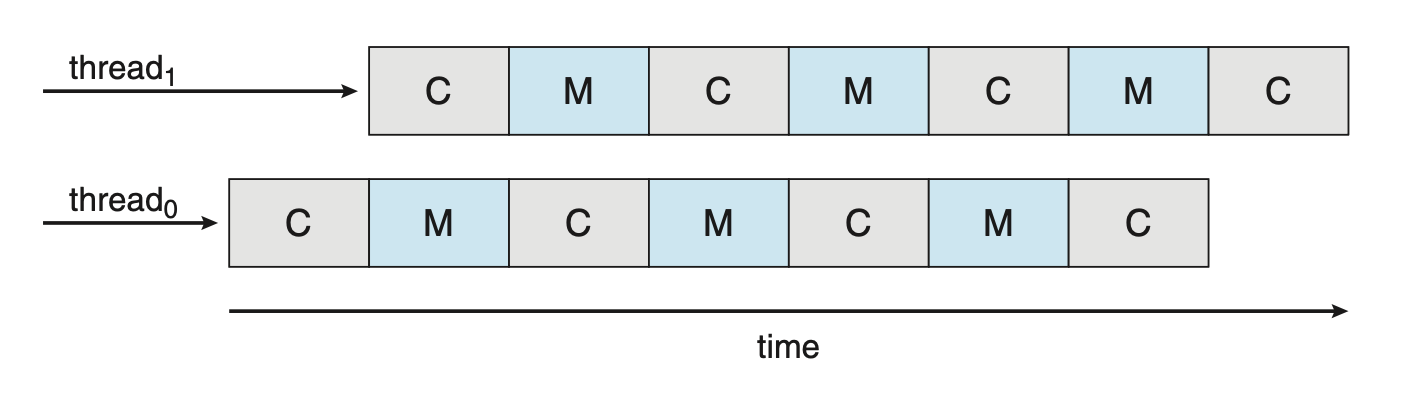
从 OS 角度看,每个硬件线程都维护其自身的架构状态,如同可运行软件线程的逻辑 CPU 一般的存在。这种被称为芯片多线程(chip multithreading, CMT) 的技术如右图所示:该处理器包含 4 个计算核心,每核配备 2 个硬件线程;对 OS 而言,这相当于拥有 8 个逻辑 CPU 可用。
总的来说,处理核心实现多线程的方式主要有两种:
- 粗粒度(coarse-grained) 多线程:在某个核心上执行一个线程,直至遇到如内存停顿这样的长久等待事件
- 由于这类事件造成的延误,核心必须切换到另一个线程开始执行
- 但这种切换的成本较高,因为在另一线程能在处理器核心上开始执行之前,指令流水线必须被清空(flush);一旦新线程启动执行,它便开始用自身的指令填充流水线
- 细粒度(fine-grained)(或称交错式)多线程:在更精细的级别上进行切换——通常是在指令周期边界处进行切换
- 由于架构设计中包含了线程切换的逻辑,因此线程间切换的成本较低
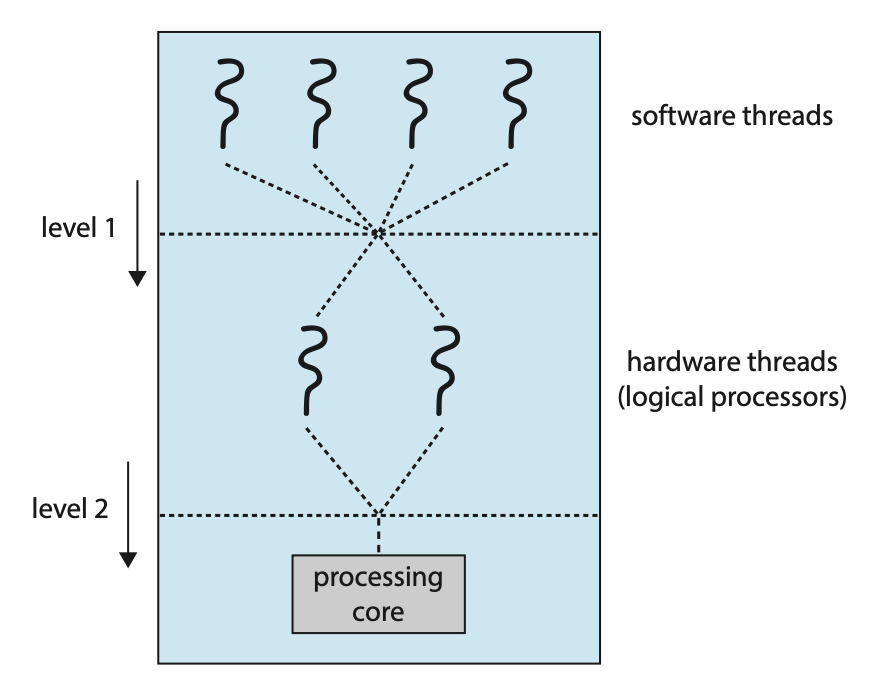
需要注意的是,物理核心的资源(如高速缓存和流水线)必须在其硬件线程之间共享,因此一个处理核心一次只能执行一个硬件线程。这样一来,多线程、多核处理器实际上需要两个不同层次的调度安排,如右图所示的双线程处理核心示意图。
- 第 1 级:OS 必须做出调度决策,选择在每一个硬件线程(逻辑 CPU)上运行哪个软件线程,此时 OS 可以采用任何调度算法
- 第 2 级:规定每个核心如何决定运行哪个硬件线程,可采用的策略有:
- 采用简单的 RR 算法来为处理核心分配硬件线程
- (见于 Intel Itanium 处理器)每个硬件线程被赋予一个从 0 到 7 的动态紧急 (urgency) 值,其中 0 代表最低紧急程度,而 7 则表示最高。
- 处理器可识别 5 种可能触发线程切换的不同事件,其中之一发生时,线程切换逻辑会比较两个线程的紧急程度,并选择具有最高紧急值的线程在处理器核心上执行
上述两级调度不一定相互排斥。
Load Balancing⚓︎
在 SMP 系统中,保持所有处理器之间工作负载均衡非常重要,以充分利用多处理器的优势。在 SMP 系统中,负载均衡(load balancing) 技术试图将工作负载均匀分布在所有处理器上。
- 需要注意的是,负载均衡通常仅在系统中每个处理器都有自己的私有就绪队列并包含可执行的线程时才是必要的
- 在具有公共运行队列的系统中,负载均衡不是必要的,因为一旦处理器空闲,它会立即从公共就绪队列中提取一个可运行的线程
负载均衡的实现方法有:
- 推送迁移(push migration):一个特定任务会周期性地检查每个处理器的负载情况,一旦发现不均衡,便通过将线程从过载处理器移动(或推送)至空闲或较不繁忙的处理器来实现负载均匀分配
- 拉取迁移(pull migration):空闲处理器从忙碌处理器处获取等待任务
这两种迁移方式并非互斥,反而实际上在负载均衡的系统中常常一起实现。
“平衡负载”的概念可能有不同的含义。
- 一种观点认为,平衡负载可能仅要求所有队列拥有大致相同数量的线程
- 另一种看法则要求在所有队列中平均分配线程优先级
- 或许在某些情况下,这两种策略都不足够充分,甚至可能与调度算法的目标背道而驰
Processor Affinity⚓︎
-
考虑一个线程在特定处理器上运行时,高速缓存会发生什么变化
- 线程最近访问的数据会填充该处理器的高速缓存,因此该线程后续的内存访问常常能在高速缓存中得到满足(这被称为“热缓存(warm cache)”)
-
现在设想一下,如果由于负载均衡等原因,线程迁移到了另一个处理器上会发生什么情况
- 这时,第一个处理器的高速缓存内容必须被置为无效 (invalidate),而第二个处理器的高速缓存则需要重新填充数据
- 鉴于使高速缓存失效和重新填充的高成本,大多数支持 SMP 的 OS 都会尽量避免将线程从一个处理器迁移到另一个处理器,而是努力让线程持续在同一处理器上运行,以利用热缓存的优势
- 这体现了处理器亲和性(processor affinity),即进程对其当前运行的处理器的亲和性
之前介绍的线程调度队列组织策略对处理器亲和性有所影响。
- 若采用公共就绪队列的方式,任何处理器都有可能选中某个线程来执行。因此,当线程被调度到新的处理器上时,该处理器的缓存需重新填充数据。
- 而如果使用私有的、每个处理器独享的就绪队列,则线程始终在同一处理器上被调度,从而能充分利用热缓存中的数据内容,因而自然地体现了处理器亲和性的优势
处理器亲和性有多种形式:
- 软亲和性(soft affinity):OS 试图让进程在同一处理器上运行(但并不保证一定会如此
) ,但在负载均衡过程中,进程仍有可能在不同处理器间迁移 - 硬亲和性(hard affinity):一种系统调用,允许进程指定其可运行的一组处理器子集
许多系统同时提供软、硬两种亲和性机制。例如 Linux 实现了软亲和性,同时也提供了 sched_setaffinity() 系统调用,通过允许线程指定其有资格运行的 CPU 集合来支持硬亲和性。
系统的主内存架构同样会影响处理器的亲和性问题。下图展示了一种非均匀内存访问(NUMA)架构,其中包含两个物理处理器芯片,每个芯片都配备了自己的 CPU 和本地内存。
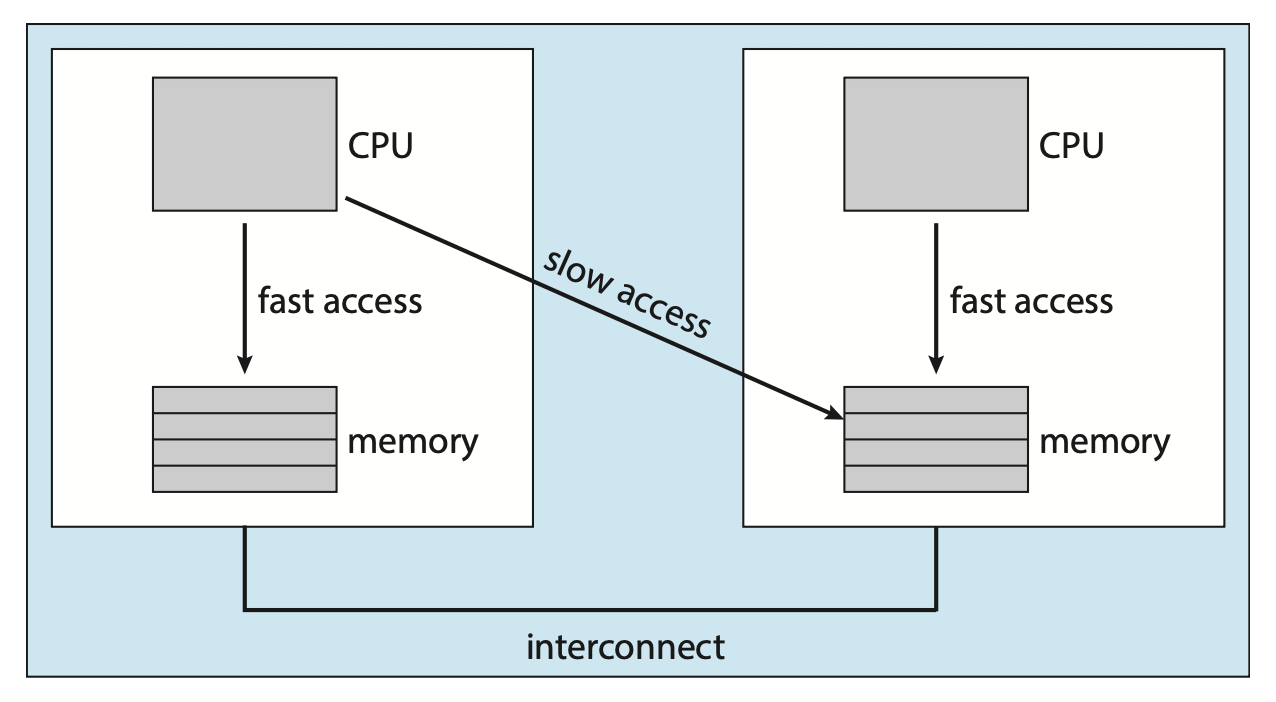
尽管通过系统互连使得 NUMA 系统中的所有 CPU 能够共享一个物理地址空间,但 CPU 访问其本地内存的速度要快于访问其他 CPU 的本地内存。如果 OS 的 CPU 调度器和内存分配算法具备 NUMA 感知能力(NUMA-aware) 并协同工作,那么被调度到特定 CPU 上的线程便可以被分配到最靠近该 CPU 的内存区域,从而为线程提供最快的内存访问速度。
值得注意的是,负载均衡常常会抵消处理器亲和性带来的好处。也就是说,让线程在同一处理器上运行的好处在于,该线程能够利用其数据已存在于该处理器缓存中的优势。通过将线程从一个处理器迁移到另一个来实现负载均衡,则会消除这一优势。因此,针对现代多核 NUMA 系统的调度算法变得相当复杂。
Heterogeneous Multiprocessing⚓︎
目前讨论的内容中,所有处理器在功能上都是相同的,因而允许任何线程在任何处理核心上运行。唯一的区别在于内存访问时间可能会因负载均衡和处理器亲和性策略的不同而有所变化。
尽管移动设备系统现已采用多核架构,但有些系统的设计采用了运行相同指令集的核心,这些核心在时钟速度和电源管理方面存在差异,包括能够调整核心的功耗直至使其进入空闲状态。这类系统被称为异构多处理(heterogeneous multiprocessing, HMP)。HMP 的设计初衷是通过根据任务的具体需求,将其分配给特定核心以更好地管理能耗。
对 ARM 处理器而言,这类架构被称为 big.LITTLE,它将高性能的大核(big core) 与节能的小核(LITTLE core) 相结合。大核能耗较高,因此仅适合短时间使用;相应地,小核能耗较低,故可长时间运行。
这种方法具有多重优势:
- 通过将多个较慢的核心与更快的核心相结合,CPU 调度器能够将那些不需要高性能但可能需要长时间运行的任务(如后台任务)分配给小核,从而节省电池电量
- 同样地,对于需要更多处理能力,但可能运行时间较短的交互式应用,则可以分配给大核
- 此外,如果移动设备处于节能模式,可以关闭能耗高的大核,系统仅依赖能效高的小核
Real-time CPU Scheduling⚓︎
实时 OS 可分为:
- 软实时系统(soft real-time system):无法保证关键的实时进程何时被调度,仅确保在处理时会优先于非关键的进程
- 硬实时系统(hard real-time system):任务必须在截止时间(deadline) 前完成服务,超过 ddl 的服务等同于未提供服务
下面将来探讨有关两类实时系统相关的进程调度问题。
Minimizing Latency⚓︎
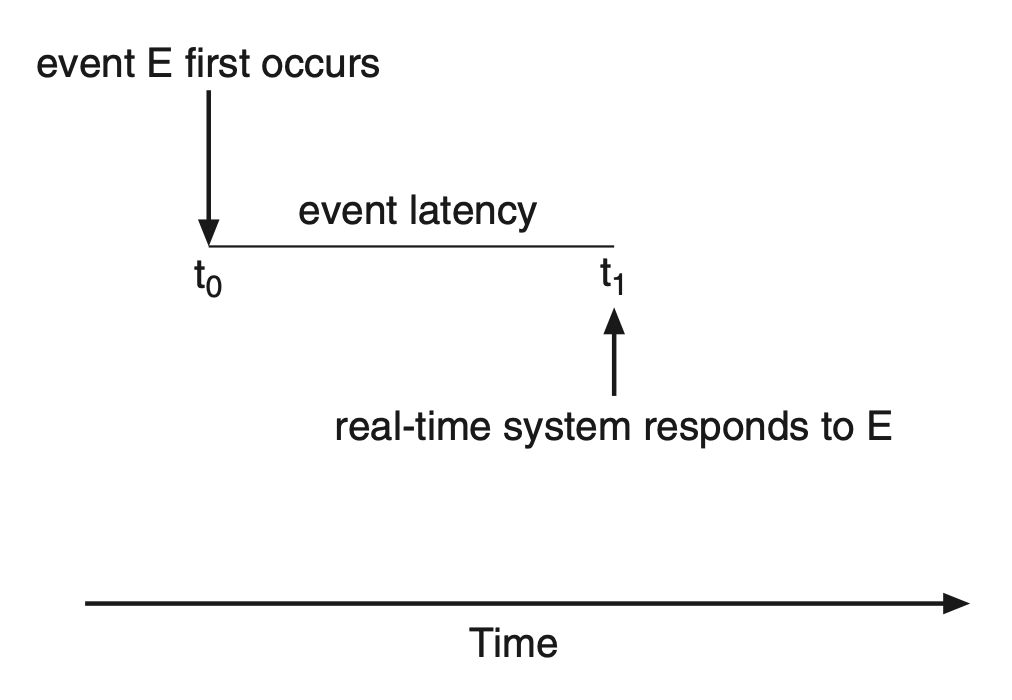
考虑实时系统的事件驱动(event-driven) 特性:
- 系统通常处于等待实时事件发生的状态
- 事件可能源于软件(例如定时器到期
) ,也可能来自硬件 - 一旦事件发生,系统必须尽快响应并处理它
- 事件时延(event latency):从事件发生至得到处理所经过的时间
有两类影响实时系统性能的时延,它们都需要得到最小化:
-
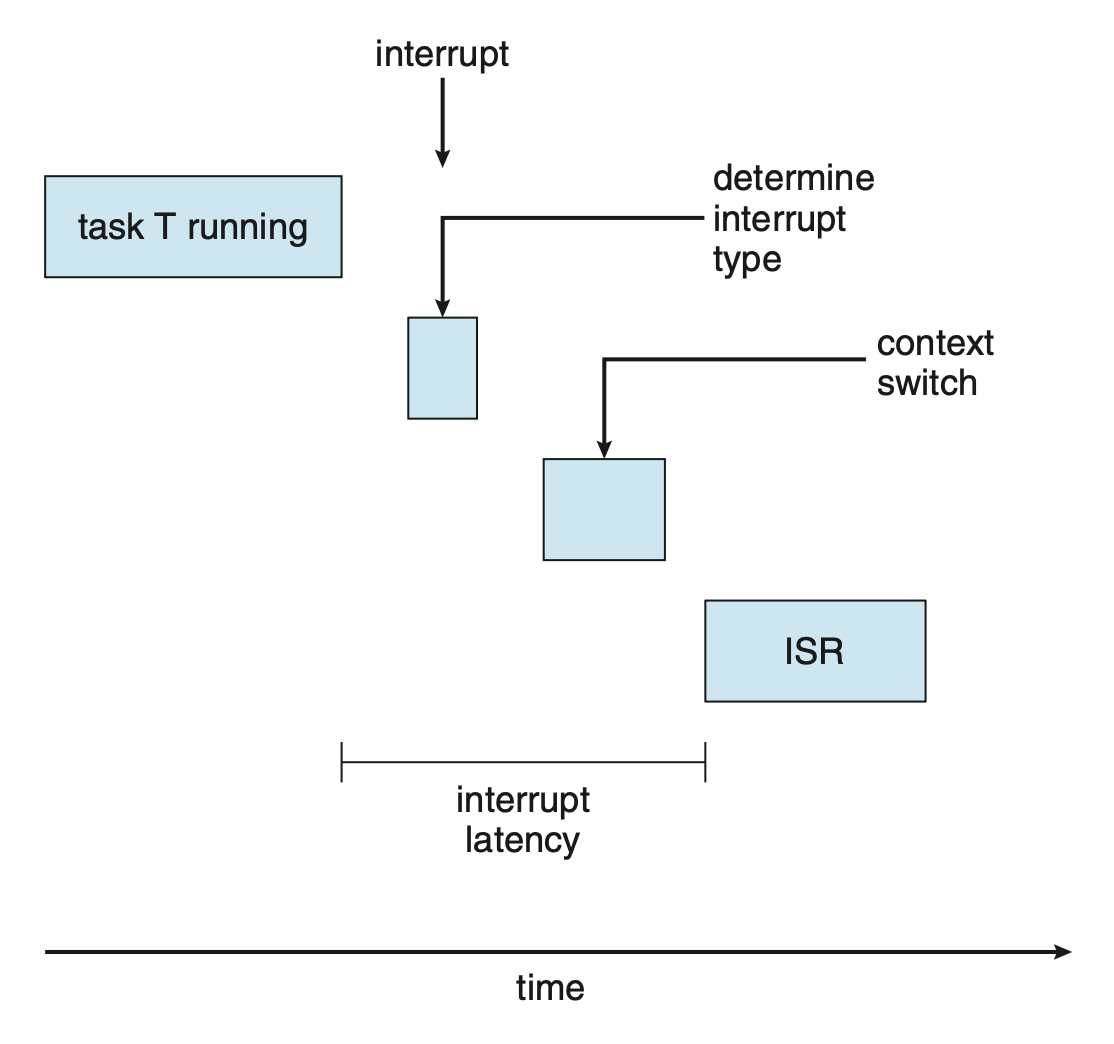
中断时延(interrupt latency):从中断到达 CPU 开始,到执行处理该中断的服务程序之间的时间间隔
- 当中断发生时,OS 必须先完成当前正在执行的指令,并判断发生的中断类型;接着在通过特定的中断服务程序(interrupt service routine, ISR) 处理中断之前保存当前进程的状态;而完成这些任务所需的总时间即为中断时延
- 导致中断时延的一个重要因素是在更新内核数据结构时,中断被禁用的时长
- 实时 OS 要求仅在极短的时间内禁用中断
-
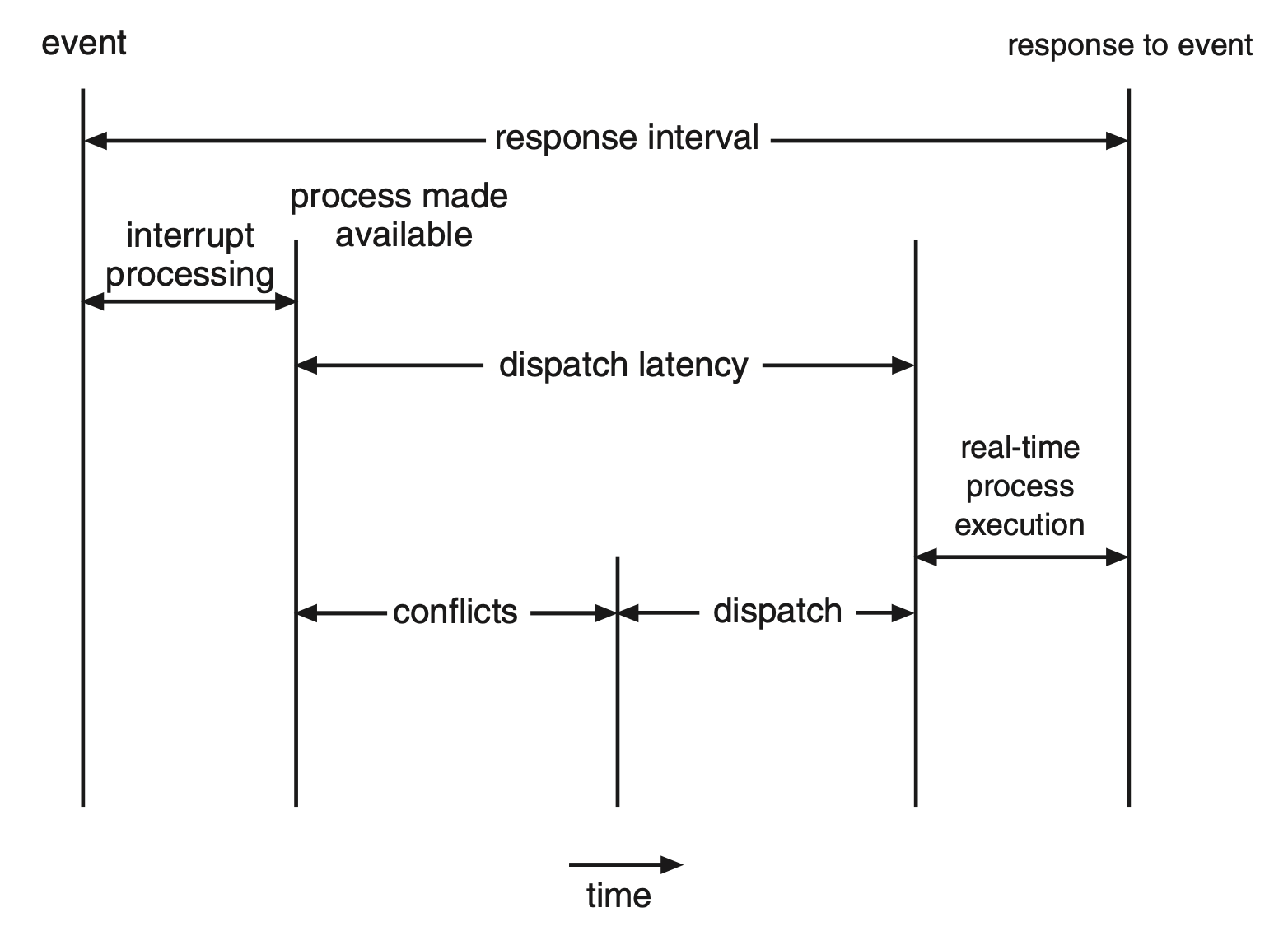
分派时延(dispatch latency):分派程序停止一个进程,并启动另一个所需的时间
- 保持低分派时延的最有效的方法是采用抢占式内核
- 分派时延的冲突阶段(conflict phase) 包含两个部分:
- 抢占任何在内核中运行的进程
- 释放高优先级进程所需的,但目前为低优先级进程所用的资源
Priority-Based Scheduling⚓︎
实时 OS 的特性决定了调度器必须支持基于优先级的抢占式算法。然而,仅提供这种算法只能满足软实时系统的要求;硬实时系统必须进一步保证实时任务在截止日期前得到服务,因而需要额外的调度功能,因此下面主要介绍适用于硬实时系统的调度算法。
在深入探讨各个调度器之前,必须明确待调度进程的一些特性。
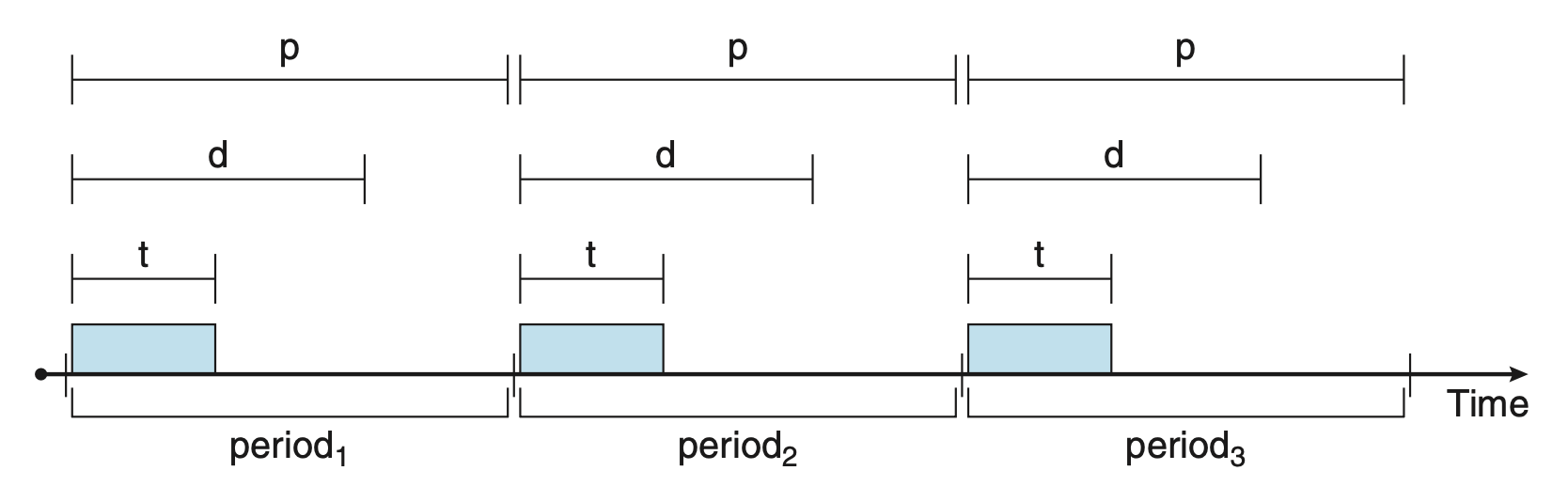
- 首先,实时系统中的进程是周期性的(periodic),这意味着它们以固定的间隔(周期)使用 CPU 资源
- 一旦进程获得了 CPU 使用权,它就有了固定的处理时间 \(t\)、截止日期 \(d\) 和周期 \(p\),它们的关系为:\(0 \le t \le d \le p\)
- 周期性任务的速率 (rate) 为 \(\dfrac{1}{p}\)
下图展示了周期性进程随时间的执行情况:
这种调度方式的不同之处在于:进程需要向调度器声明其 ddl,随后调度器会运用准入控制(admission-control) 算法,执行以下两种操作之一:
- 接纳该进程,并确保其能按时完成
- 在无法保证任务能在 ddl 内得到处理时,拒绝这一请求
Rate-Monotonic Scheduling⚓︎
单调速率(rate-monotonic) 调度算法采用静态优先级策略,并允许抢占以安排周期性的任务。
- 每个周期性任务在进入系统时,会根据其周期长短反向分配优先级:周期越短,优先级越高;周期越长,优先级越低
- 这一策略的基本原理在于为更频繁需要 CPU 的任务赋予更高的优先权
- 此外还假设每个周期性进程的 CPU 突发持续时间均保持一致
例子
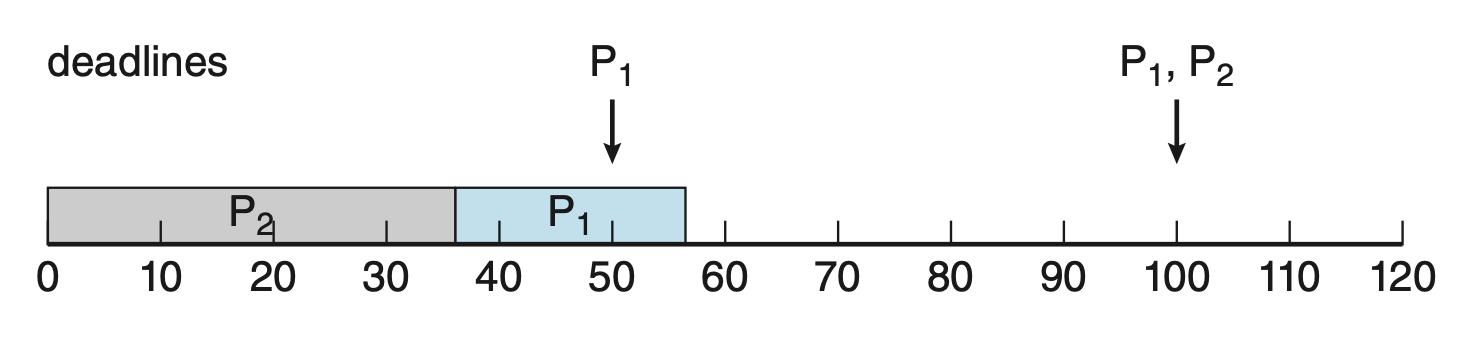
假如有两个进程 \(P_1, P_2\),它们的周期分别为 50 和 100,且处理时间分别为 20 和 35,即 \(p_1 = 50, p_2 = 100, t_1 = 20, t_2 = 35\)。
如果用 CPU 突发和周期之比来衡量 CPU 利用率,对于这个例子,CPU 利用率 = 20 / 50 + 35 / 100 = 75%。因此我们能够通过调度让这些进程在 ddl 前完成,且还有空余周期。
假如 \(P_2\) 优先级高于 \(P_1\),那么它们的执行情况如下所示。可以看到此时 \(P_1\) 未能在 ddl 前完成。
如果采用单调速率调度,那么 \(P_1\) 优先级会高于 \(P_2\),执行结果如下。可以看到此时两个进程均在 ddl 前完成了。

单调速率调度被认为是最优的,因为如果一组进程无法通过此算法进行调度,那么任何其他分配静态优先级的算法也无法对其进行调度。
下面来看一组无法使用单调速率算法调度进程的例子:
例子
依旧考虑两个进程 \(P_1, P_2\),参数为 \(p_1 = 50, t_1 = 25, p_2 = 80, t_2 = 35\)。
- CPU 利用率 = 25 / 50 + 35 / 80 = 94%
- 根据单调速率调度,\(P_1\) 优先级更高
下面是执行情况,其中 \(P_2\) 无法在 ddl 前完成。

根据前面的例子,可以发现该调度的局限在于 CPU 利用率是有上限的,所以有时无法完全最大化利用 CPU 资源。在调度 N 个进程时,最坏情况下的 CPU 利用率为 \(N(2^{1/N} - 1)\)。在系统中仅有一个进程时,CPU 利用率为 100%;但随着进程数量趋近于无穷大,利用率降至约 69%(
Earliest-Deadline-First Scheduling⚓︎
最早截止日期优先(earliest-deadline-first, EDF) 调度根据截止日期动态分配优先级:截止日期越早,优先级越高;截止日期越晚,优先级越低。在 EDF 策略下,当一个进程变为可运行时,它必须向系统告知其 ddl。
例子
同“单调速率调度”一节的第二个(失败)例子,但采用 EDF 调用,结果如下:

- \(P_1\) ddl 更早,所以优先级更高
- 第一次运行 \(P_2\) 不会被 \(P_1\) 抢占,而是让 \(P_2\) 完成 \(t_2\) 的运行时间,因为 \(P_1\) 的第二个 ddl(100)比 \(P_2\) 的第一个 ddl(80)晚
- 但第二次运行 \(P_2\) 会被 \(P_1\) 抢占,因为 \(P_1\) 的第三个 ddl(150)比 \(P_2\) 的第二个 ddl(160)早
EDF 调度不要求进程必须是周期性的,也不要求每个进程在每次执行期间需要固定的 CPU 时间。唯一的要求是当一个进程变为可运行时,需向调度器声明其截止时间。
EDF 调度的吸引力在于它在理论上是最优的——它能使每个进程都能满足其截止日期的要求,并且 CPU 利用率达到 100%。然而在实践中,由于进程间上下文切换和中断处理的耗时,因而无法达到理想的 CPU 利用率水平。
Proportional Share Scheduling⚓︎
比例份额(proportional share) 调度器通过在所有应用程序间分配 \(T\) 份份额来运作,而每个应用程序可获得 \(N\) 份时间份额,从而确保该应用将拥有总处理器时间的 \(\dfrac{N}{T}\)。
比例份额调度器必须与准入控制策略协同工作,以确保应用程序获得其分配的时间份额。只有当有足够的份额可用时,准入控制策略才会接纳请求特定数量份额的客户端。
例子
假设总共有 \(T=100\) 的份额要分配给三个进程 A、B 和 C。A 被分配 50 份,B 得到 15 份,C 获得 20 份。这一机制保证了 A 将占据总处理器时间的 50%,B 占 15%,而 C 则占 20%。
由于已经分配了 50 + 15 + 20 = 85 份,如果新进程 D 请求 30 份,准入控制器将拒绝 D 进入系统(因为只剩下 15 份了
POSIX Real-Time Scheduling⚓︎
POSIX 定义了 2 个用于实时线程的调度类:
SCHED_FIFO:与 FCFS 策略关联,采用 FIFO 队列SCHED_RR:与 RR 策略关联
此外还提供了 SCHED_OTHER 调度类,但没有规定实现,由系统自己定义。
POSIX API 指定获取和设置调度策略的两个函数:
pthread_attr_getschedpolicy(pthread attr t *attr, int *policy)pthread_attr_setschedpolicy(pthread attr t *attr, int policy)
例子
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
int main(int argc, char *argv[]) {
int i, policy;
pthread_t tid[NUM THREADS];
pthread_attr_t attr;
/* get the default attributes */
pthread_attr_init(&attr);
/* get the current scheduling policy */
if (pthread_attr_getschedpolicy(&attr, &policy) != 0)
fprintf(stderr, "Unable to get policy.\n");
else {
if (policy == SCHED_OTHER)
printf("SCHED_OTHER\n");
else if (policy == SCHED_RR)
printf("SCHED_RR\n");
else if (policy == SCHED_FIFO)
printf("SCHED_FIFO\n");
}
/* set the scheduling policy - FIFO, RR, or OTHER */
if (pthread_attr_setschedpolicy(&attr, SCHED_FIFO) != 0)
fprintf(stderr, "Unable to set policy.\n");
/* create the threads */
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i], &attr, runner, NULL);
/* now join on each thread */
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param)
{
/* do some work ... */
pthread exit(0);
}
OS Examples: Linux Scheduling⚓︎
现在 Linux 默认的调度算法是完全公平调度器(completely fair scheduler, CFS)(底层数据结构为红黑树
Linux 系统中的调度基于调度类(scheduling classes) 进行,每个类被分配一个特定的优先级。通过采用不同的调度类,内核能够根据系统及其进程的需求适应不同的调度算法。标准 Linux 内核实现了两种调度类:
- 使用 CFS 算法的默认调度类
- 实时调度类
CFS 调度器为每个任务分配一定比例的 CPU 处理时间,这一比例是根据分配给每个任务的 nice 值来计算的。
- nice 值的范围从 -20 到 +19,数值越小表示相对优先级越高
- 默认的 nice 值为 0
CFS 不使用离散的时间片值,而是设定一个目标时延(targeted latency),即所有可运行的任务至少应运行一次的间隔时长。
- CPU 时间的分配比例便是依据这个目标时延的值来确定
- 除了有默认值和最小值外,当系统中活跃任务的数量超过某一阈值时,目标时延也会相应增加
CFS 调度器并不直接分配优先级,而是通过维护每个任务的虚拟运行时间(virtual run time)(使用任务特定的变量 vruntime)来记录每个任务已运行的时间。
- 虚拟运行时间与一个基于任务优先级的衰减因子(decay factor) 相关联,低优先级任务的衰减速率高于高优先级任务
- 对于普通优先级的任务(nice 值为 0
) ,虚拟运行时间等同于实际物理运行时间 - 调度器选择具有最小
vruntime值的进程执行,且更高优先级的任务可以抢占当前正在运行的较低优先级任务
Linux 系统采用了两种独立的优先级范围:一种专用于实时任务,另一种则适用于普通任务。

- 实时任务的静态优先级设定在 0 至 99 之间
- 普通任务的优先级范围则是 100 到 139
- 任务根据其 nice 值被分配优先级,其中 -20 对应优先级 100,而 +19 则对应 139
CFS 调度器同样支持负载均衡,它采用一种精密技术来平衡各处理核心间的负载,同时兼顾 NUMA 架构并尽量减少线程迁移。CFS 将每个线程的负载定义为该线程优先级与其平均 CPU 利用率的综合考量。基于这一衡量标准,队列的负载即为队列中所有线程负载的总和,而实现均衡只需确保所有队列的负荷大致相当即可。
迁移线程可能会导致内存访问性能下降,为解决这一问题,Linux 定义了一个层次化的调度域系统。调度域(scheduling domain) 是一组可以相互之间进行负载均衡的 CPU 核心集合,如下所示:
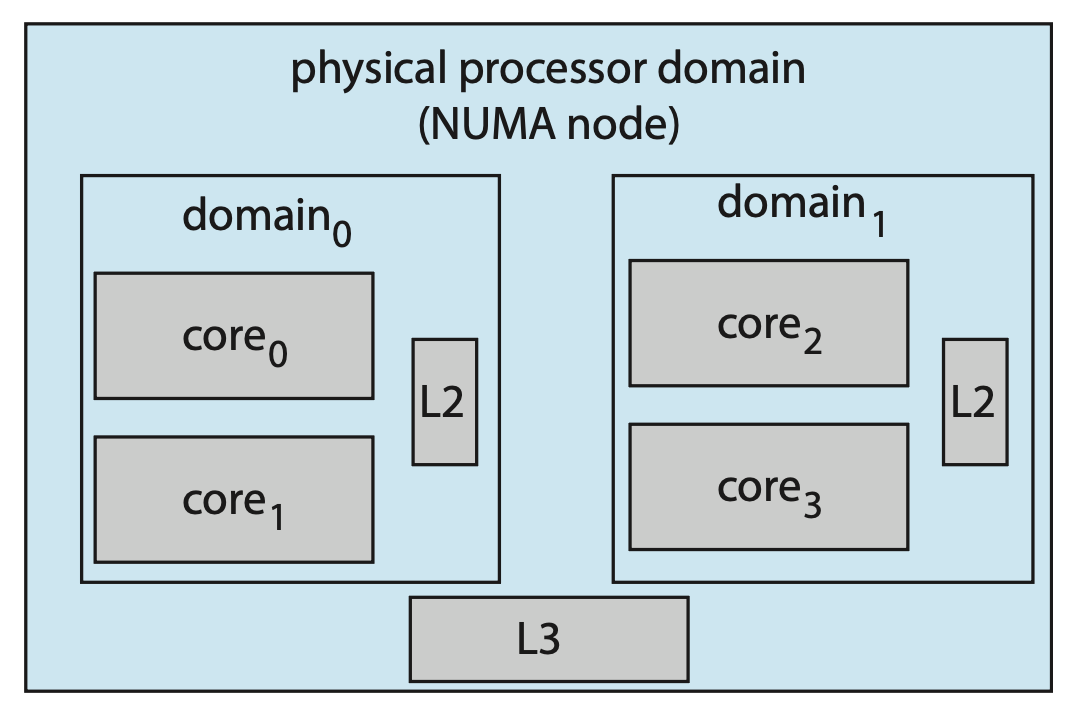
- 每个调度域中的核心根据它们共享系统资源的方式被分组
- 如上图所示,每个核心有自己的 L1 缓存,并且它们会共享二级 L2 缓存,分别对应域 0 和域 1
- 同样地,这两个域可能共享 L3 缓存,从而来到了处理器级别的域(也称为 NUMA 节点)
CFS 的总体策略是从层次结构的最低层开始,在域内平衡负载。
Algorithm Evaluation⚓︎
选择合适的 CPU 调度算法可能颇具挑战。首要问题就是明确选择算法的标准,并确定这些要素的相对重要性。一旦确定了选择标准,我们便要对算法进行评估。所以接下来就来介绍各种评估方法。
Deterministic Modeling⚓︎
一类主要的评估方法是分析性评估(analytic evaluation):利用给定的算法和系统工作负载,生成一个公式或数值来评价该算法在此工作负载下的性能。而确定性建模(deterministic modeling) 是分析性评估的其中一种类型。它采用特定的预设工作负载,以确定每个算法在该工作负载下的表现。
例子
假如以下一组进程在时刻 0 到达,它们的 CPU 突发长度(单位:ms)如下所示:

以下是采用各种调度算法后的结果
-
FCFS 算法:平均等待时间为 28ms

-
SJF 算法:平均等待时间为 13ms

-
RR 算法:平均等待时间为 23ms

确定性建模方法简单快捷,能提供精确的数据,以便我们比较不同算法。然而,它需要准确的输入数据,并且其结果仅适用于特定情况。
确定性建模主要用于描述调度算法和举例说明。不过当我们反复运行同一程序并能精确测量其处理需求时,或许可以利用确定性建模来选择合适的调度算法。此外,确定性建模还能揭示出可单独分析和验证的趋势。
Queueing Models⚓︎
在许多系统中,每天运行的进程不同,因此不存在用于确定性建模评估方法的固定进程集合。然而,我们可以
- 确定 CPU 和 I/O 突发活动的分布情况。这些分布可以被测量出来,随后进行近似处理或简单估算,最终得到一个描述特定 CPU 突发概率的数学公式
- 描述进程进入系统的时间分布(即到达时间分布)
基于这两种分布,对于大多数算法而言,能够计算出平均吞吐量、利用率、等待时间等性能指标。
我们用一个服务器网络描述计算机系统:
- 每个服务器都有一列等待处理的进程队列
- CPU 作为一个服务器,拥有就绪队列;同样 I/O 系统也配备有设备队列
- 通过了解到达率和服务率,我们能够计算出利用率、平均队列长度、平均等待时间等指标
这种方法叫做排队网络分析(queueing-network analysis)。设 \(n\) 为平均长期队列的长度,\(W\) 为队列中的平均等待时间,\(\lambda\) 为队列中新进程的平均到达率。我们预期:在一个进程等待的 \(W\) 时间内,将有 \(\lambda \times W\) 个新进程进入队列。若系统处于稳定状态,那么离开队列的进程数量必须等于到达的进程数量。因此, $$ n = \lambda \times W $$
这个等式称为利特尔公式(Little's formula),适用于任何调度算法和到达分布。
不过排队分析能够处理的算法类别和分布相当有限,复杂算法和分布的数学处理起来较为困难。所以排队模型往往只是对真实系统的近似模拟,计算结果的准确性有待商榷。
Simulations⚓︎
为了更精确地评估调度算法,我们可以采用模拟(simulation) 方法
- 这涉及对计算机系统模型进行编程,而软件数据结构代表了系统的主要组成部分
- 模拟器拥有一个代表时钟(clock) 的变量,随着该变量值的增加,模拟器会修改系统状态,以反映设备、进程及调度器的活动情况
- 在模拟执行过程中,收集并打印出表明算法性能的统计数据
驱动模拟所需的数据可以通过多种方式生成。最常用的方法是利用随机数生成器
- 按照概率分布编程来产生进程、CPU 突发时间、到达与离开等事件
- 这些分布可以数学定义(如均匀分布、指数分布、泊松分布)或经验性地确定
- 若要经验性地定义一个分布,需对研究中的实际系统进行测量;测量结果将揭示真实系统中事件的分布规律
然而,上述模拟可能并不准确,因为真实系统中连续事件之间存在关联;而频率分布仅能显示每种事件发生的次数,它并未揭示事件发生的顺序信息。
为解决这一问题,我们可以采用追踪文件(trace files) 的方法:通过监控真实系统并记录实际事件的序列,创建一条追踪记录,随后利用这一序列来驱动模拟过程。这种方法能够针对其输入产生精确的结果。
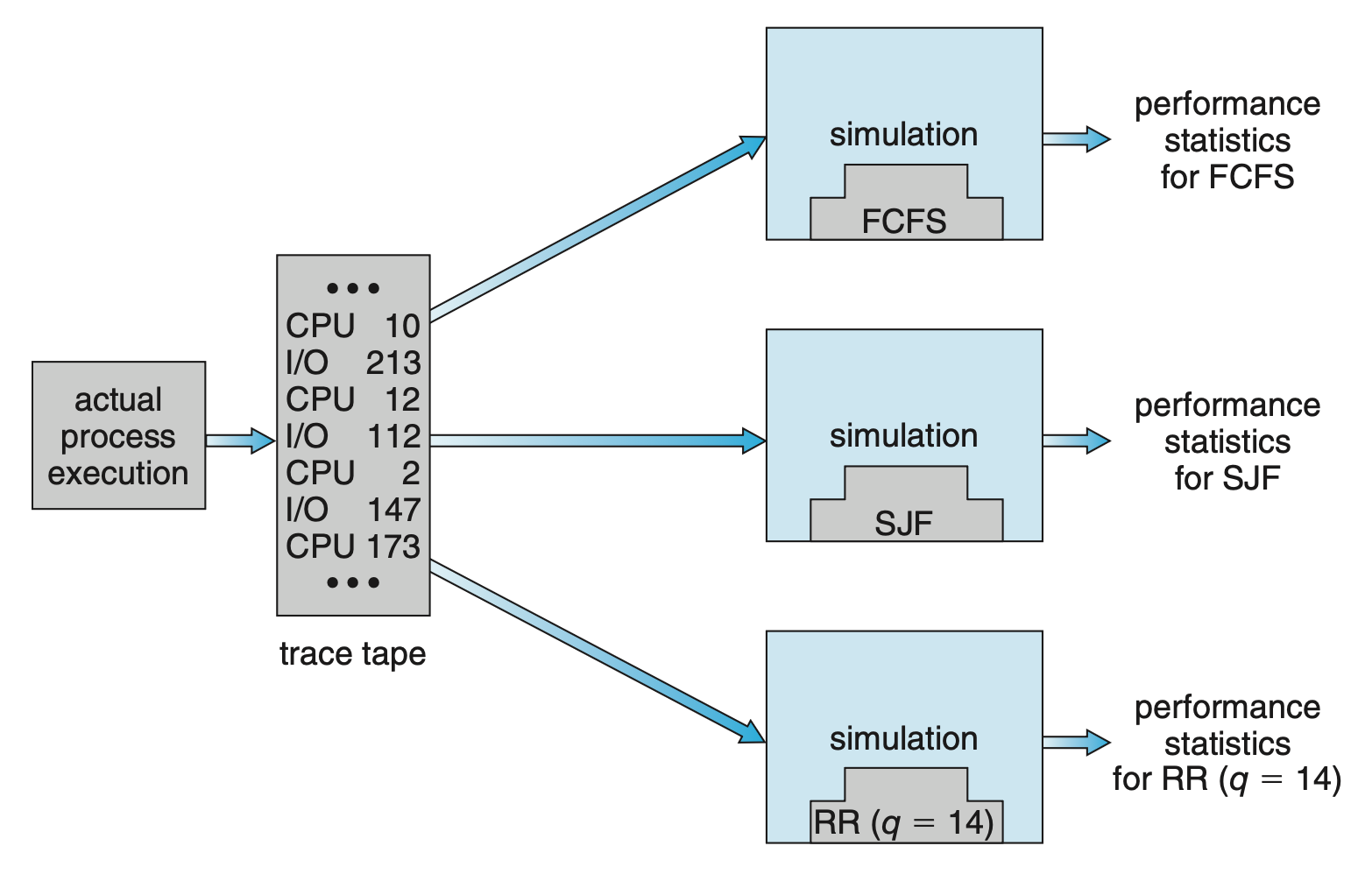
但模拟成本高,通常需要数小时。当然更详细的模拟能提供更精确的结果,但是需要耗费更多时间。此外,追踪文件会占据大量存储空间。模拟器的设计、编码和调试也是一个不小的挑战。
Implementation⚓︎
即便是模拟,精确度也有限。唯一完全准确的评估调度算法的方法是实现其代码,放入真实 OS 之中,并观察其实际运行效果。
这种方法的成本主要产生于编写算法的代码,修改 OS 以支持该算法,以及测试这些变更。通常采用回归测试(regression testing),以确认这些更改未使任何情况恶化,也未引发新的错误或导致旧错误重现。
另一个难点在于算法运行的环境会发生变化,这种变化不仅源于常规因素,还受到调度器性能的影响。
- 若优先处理短进程,用户可能会将大型进程拆分成一系列小进程
- 若交互式进程比非交互式进程优先级更高,用户则可能转向交互式操作方式
通常解决这一问题的方法是借助封装完整的操作集工具或脚本,反复运用这些工具,并在使用过程中评估效果。
评论区