Containers and Generic⚓︎
约 3005 个字 358 行代码 预计阅读时间 20 分钟
Array⚓︎
- 数组是一种特殊类型对象,能够存储固定数量的元素
-
数组应当通过
new在堆上动态分配或聚合初始化(aggregate initialization) 被创建 -
数组内所有元素类型相同
-
数组是一个对象
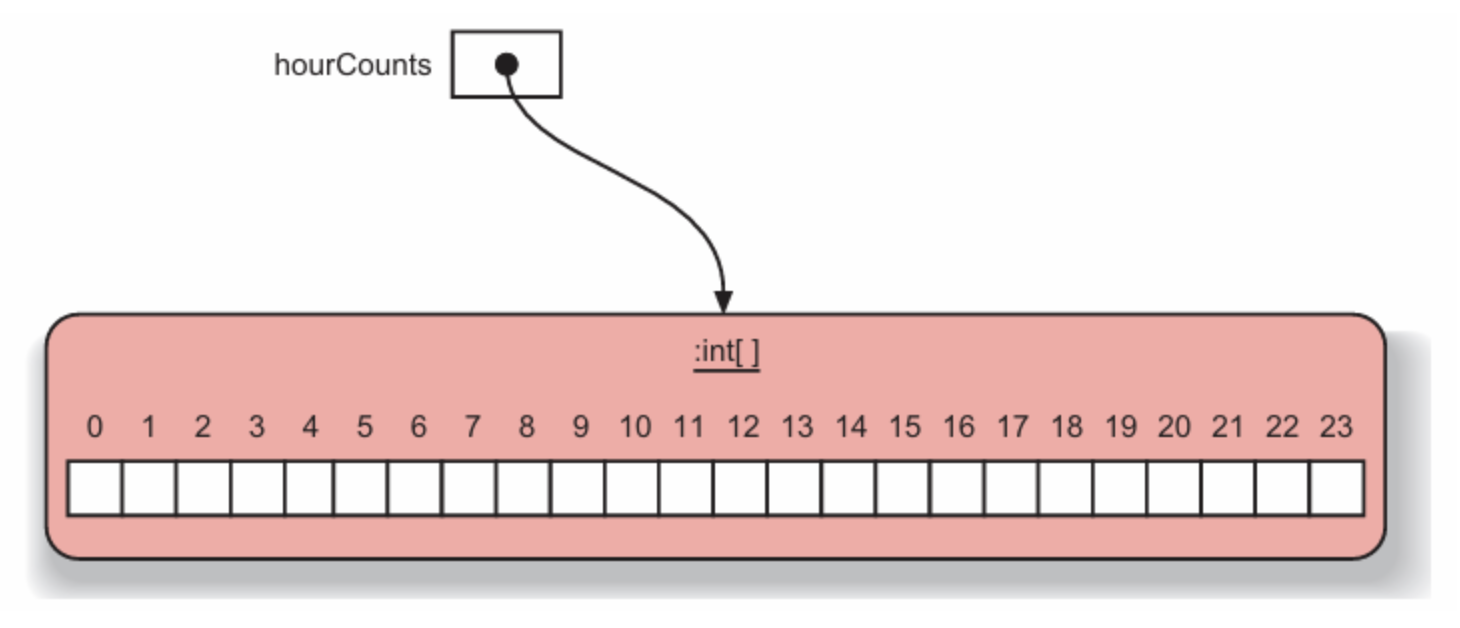
-
所有数组都有一个内部成员属性
length,表示数组大小 -
合法下标值(valid subscript value)
- 编译器会检查是否用的是合法下标值,无论用于右值还是左值
- 一旦程序运行过程中存在非法下标,就可能会出现数据或代码遭破坏,或程序中止 (abort) 的情况
- 所以 Java 有责任确保程序在运行时只使用合法下标值
- 关键概念:通过边界检查确保索引用于指代范围内的数组元素
-
for-each 语法:
-
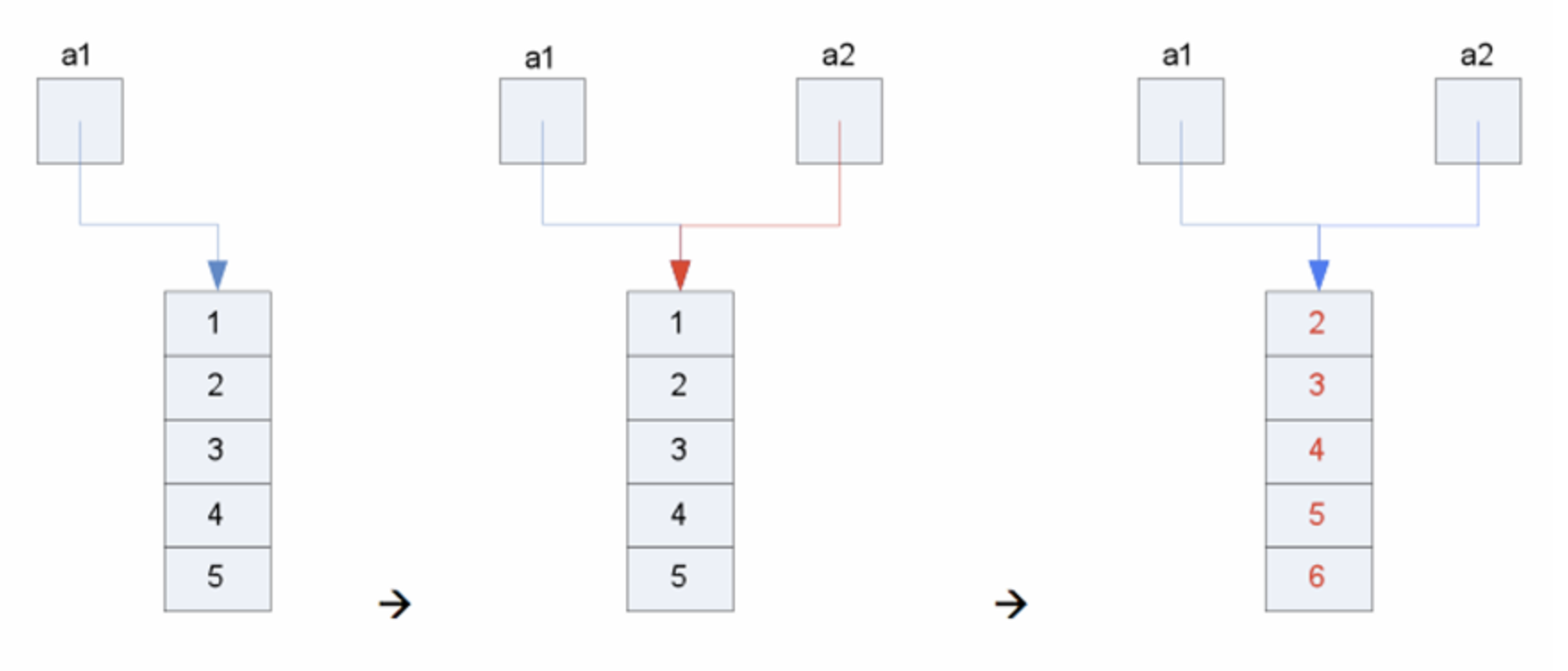
数组变量
- 是指向数组对象的指针
- 所以 Java 允许数组间的赋值
-
对象数组
- 数组可以将对象的引用(references to objects)(句柄 (handle))作为元素存储
-
注意:实例化一个对象数组仅预留了存储引用的空间,所以必须要单独实例化每个元素中要存储的对象,比如以下声明:
-
对象数组中的 for-each
class Value { int i; } Value[] a = new Value[5]; for ( int i = 0; i < a.length; i++ ) a[i] = i; for ( var x: a ) x.i++; for ( var x: a ) System.out.println(x.i);var可自动推断类型(和 C++ 的auto类似)
Collections⚓︎
容器对象(collection object) 是指能存储任意数量的其他对象的对象。常用的容器对象包括:
List:以特定顺序存储元素Set:不允许有重复元素Map:一组“键 - 值”对象对
容器类是泛型类(generic class)。
要定义一个容器类的变量,我们需要指定两种类型:
- 集合本身的类型(此处为
ArrayList) - 存储在集合中的元素类型(此处为
String)
由于 Java 有类型推断功能,所以无需在 new 中重复表述元素类型:
import java.util.ArrayList;
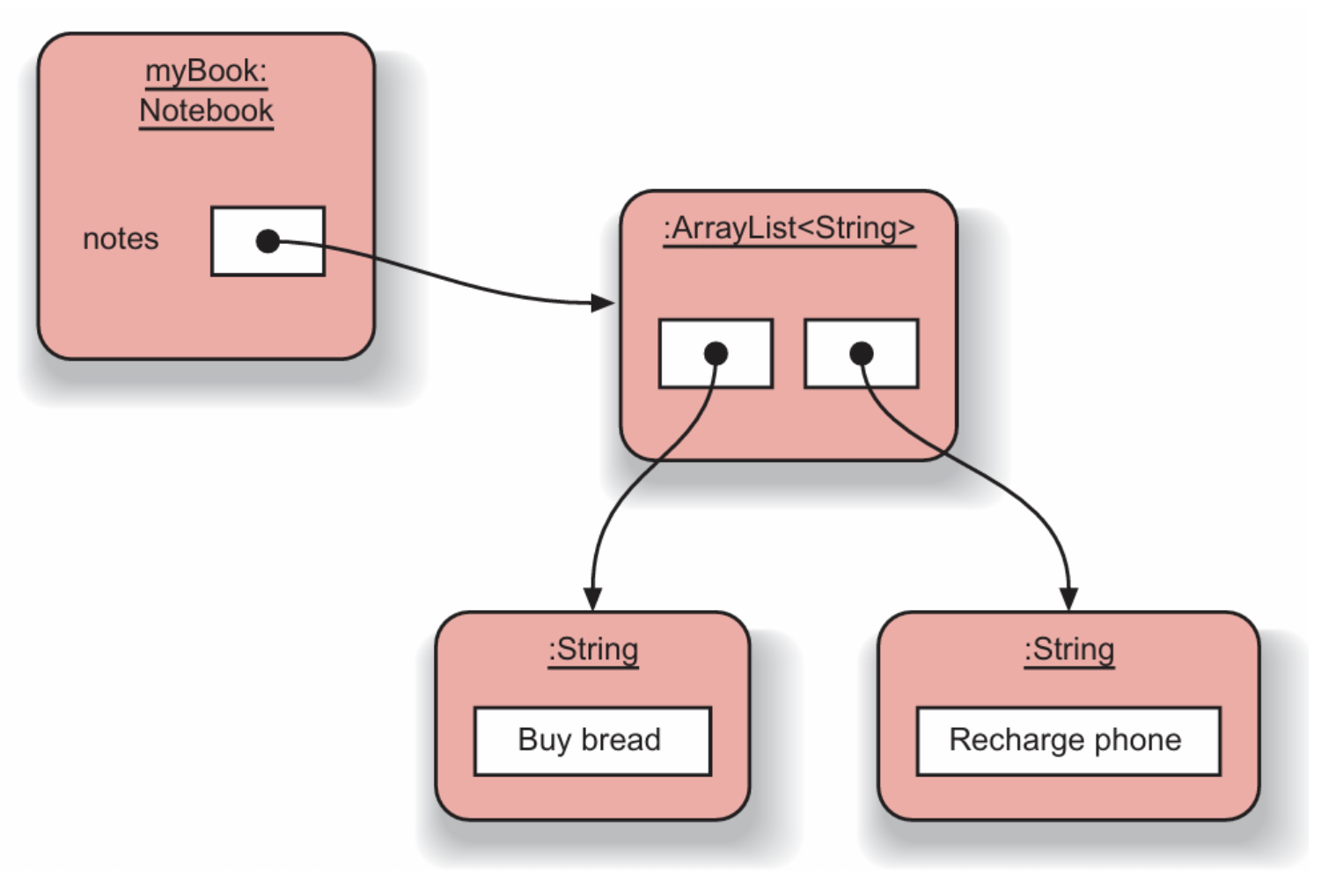
public class Notebook {
private ArrayList<String> notes = new ArrayList();
}
相应的对象结构如下:
Iteration⚓︎
在容器对象上迭代:
-
索引
-
for-each
-
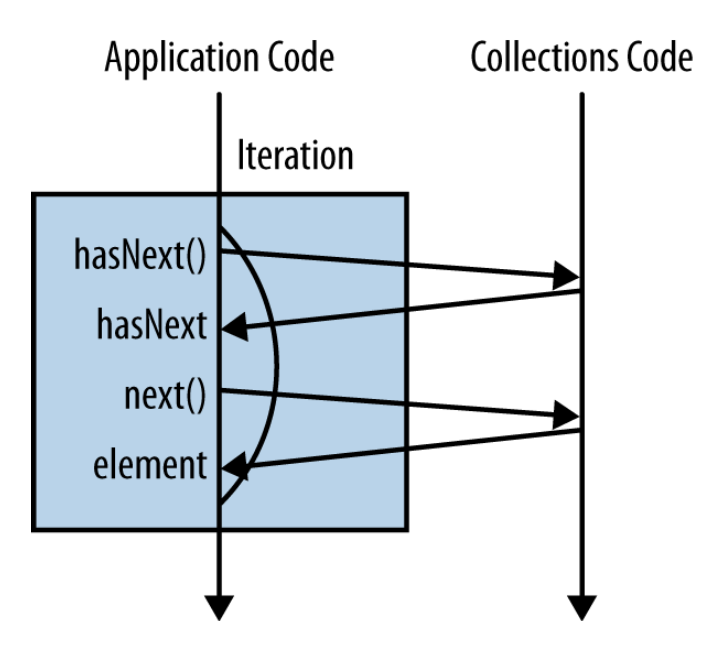
迭代器(iterator)
public void listNotes() { Iterator<String> it = notes.iterator(); while (it.hasNext()) { System.out.println(it.next()); } }- 迭代器是一种对象,它提供了遍历容器对象中所有元素的功能
- 此时客户端程序员无需了解或关心该被迭代序列的底层结构
- 迭代器的工作流程:
- 通过调用名为
iterator()的方法,向容器请求一个迭代器;这个迭代器将在首次调用其next()方法时,准备好返回序列中的第一个元素 - 使用
next()获取序列中的下一个对象 - 要想检查序列中是否还有更多对象,使用
hasNext()方法 - 利用
remove()移除迭代器最后返回的元素
- 通过调用名为
Implementation⚓︎
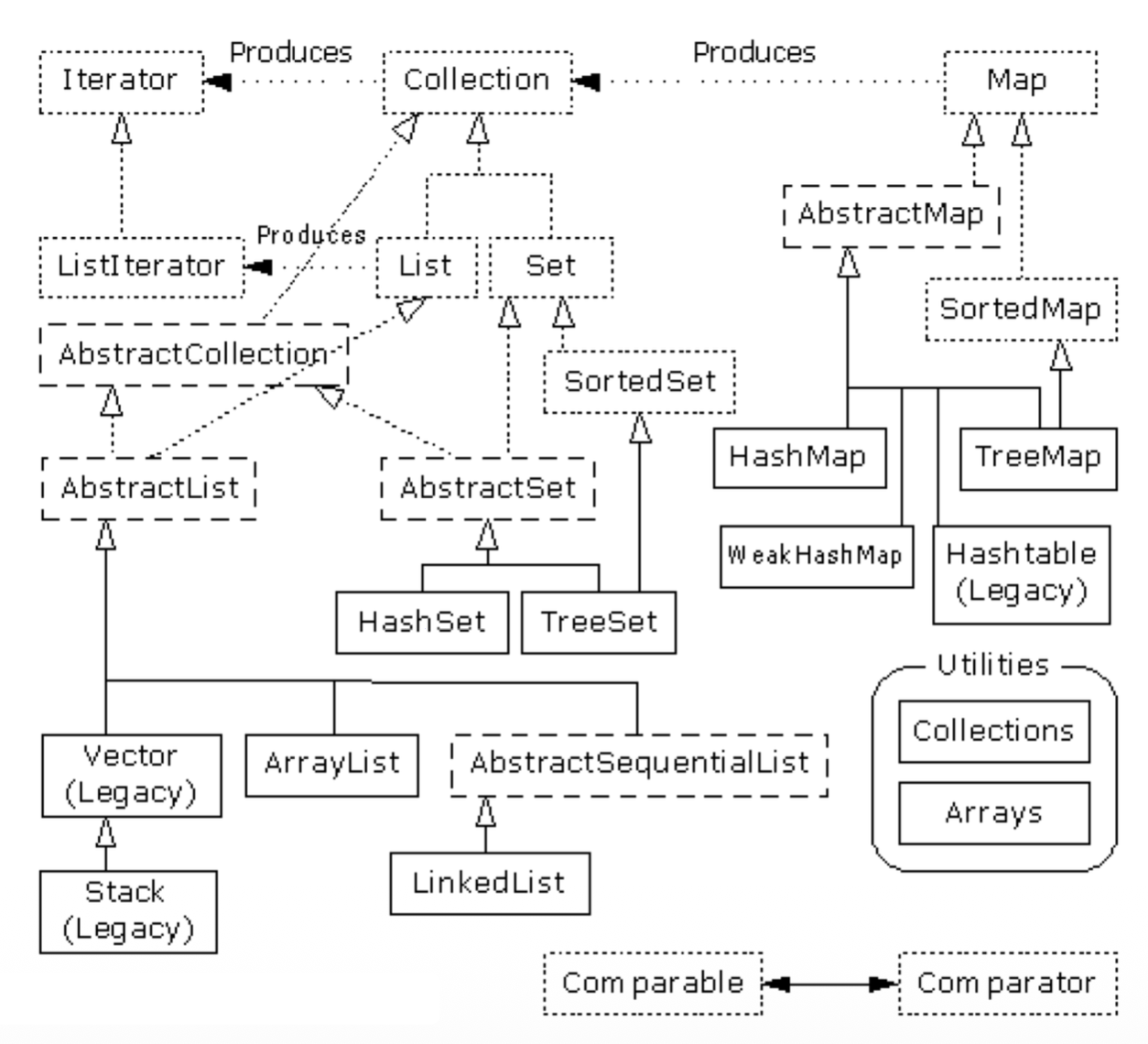
容器实现:实现集合接口的类通常以 <Implementation-style><Interface> 的形式命名。下表总结了常见容器的实现:
| Interface | Hash Table | Resizable Array | Balanced Tree | Linked List | Hash Table + Linked List |
|---|---|---|---|---|---|
| Set | HashSet |
TreeSet |
LinkedHashSet |
||
| List | ArrayList |
LinkedList |
|||
| Deque | ArrayDeque |
LinkedList |
|||
| Map | HashMap |
TreeMap |
LinkedHashMap |
容器相关术语
Utilities⚓︎
Collections 类的静态成员:
min(Collection),max(Collection)reverse()copy(List dest, List src)fill(List list, Object o)
Lists⚓︎
常用的 List 容器有:
List(接口) :以特定顺序维护元素ArrayList:使用数组实现,插入和删除偏慢LinkedList:插入和删除成本低,但随机访问慢
和其他相近容器的比较
Collection
├─ List <- 有序、可重复、带索引
│ ├─ ArrayList
│ ├─ LinkedList <- 同时也实现了 Deque
│ └─ Vector
│ └─ Stack <- Vector 的子类(古老、同步、官方不推荐)
├─Queue <- 一端进、一端出,典型 FIFO
│ ├─ Deque <- 双端队列,两头都能进出
│ │ ├─ ArrayDeque <- 数组实现,非同步,最快
│ │ └─ LinkedList <- 链表实现,也能当 List 用
│ │
│ ├─ PriorityQueue <- 按优先级出队,不是 FIFO
│ └─ ConcurrentLinkedQueue...(并发包里的实现)
ArrayList⚓︎
官方文档:https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html
下面罗列 ArrayList 常用的 API:
-
添加
-
删除
-
修改
-
查找
-
信息
-
容量
-
生成
-
迭代
-
流
ArrayList v.s. Vector
对于新代码,推荐使用
ArrayList或CopyOnWriteArrayList/Collections.synchronizedList,而非Vector。
实际选型:
- 单线程 ->
ArrayList - 多线程且读远多于写 ->
CopyOnWriteArrayList - 多线程读写均衡 ->
Collections.synchronizedList(new ArrayList<>()) - 老代码 / 需要与遗留 API 对接 -> 才继续用
Vector
Sets⚓︎
常用的 Set 容器有:
Set(接口) :加入Set的所有元素都是唯一的HashSet:对象必须定义hashCode()TreeSet:由树结构支持的有序集合
例子
如何选择合适的 Sets?
- 日常去重:
HashSet - 去重 + 插入顺序:
LinkedHashSet - 去重 + 排序 / 区间
: TreeSet(单线程)或ConcurrentSkipListSet(并发) - 并发去重:首选
ConcurrentHashMap.newKeySet()(JDK8 + 工厂方法) ,或ConcurrentSkipListSet - 读多写少且集合小:
CopyOnWriteArraySet enum专用:EnumSet.allOf(MyEnum.class)
如果要将用户自定义对象放入 Set 中,需注意:
-
必须
-
正确覆写
equals(),包括以下约定(Object规范节选) :- 自反:
x.equals(x)必须true - 对称:
x.equals(y)<=>y.equals(x) - 传递:
x.equals(y) && y.equals(z)=>x.equals(z) - 一致:多次调用结果不变
- 与
null比较必须返回false
- 自反:
-
一致地覆写
hashCode()- 规则:相等对象必须返回相同哈希值,不相等对象尽量分散
- 一旦对象进入
HashSet,不要修改参与hash/equals的字段,否则“内存泄漏”式丢失对象
-
-
可选(若想让
TreeSet/ConcurrentSkipListSet能排序,以下两者二选一即可)-
实现
Comparable<T> -
提供外部
Comparator
-
完整示例
public final class MyKey implements Comparable<MyKey> {
private final String name; // 参与 hash/equals/compare
private final int age;
public MyKey(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) { /* 见上 */ }
@Override
public int hashCode() { /* 见上 */ }
@Override
public int compareTo(MyKey o) { /* 见上 */ }
}
Maps⚓︎
常用的 Map 容器有(和 Set 类似
Map(接口)HashMapTreeMap
例子
HashMap <String, String> phoneBook = new HashMap<String, String>();
phoneBook.put("Charles Nguyen", "(531) 9392 4587");
phoneBook.put("Lisa Jones", "(402) 4536 4674");
phoneBook.put("William H. Smith", "(998) 5488 0123");
String phoneNumber = phoneBook.get("Lisa Jones");
System.out.println(phoneNumber);
哈希 (hashing) 和哈希码 (hash code):
- 键需要有
hashCode()方法 - 要想将用户自定义类作为
HashMap的键,必须覆写equals()和hashCode()
选择 Map 类
| 实现类 | 底层结构 | Key 可为 null | 有序性 | 备注 |
|---|---|---|---|---|
HashMap |
数组 + 链表 + 红黑树(JDK8+) | 允许一个 | 无顺序 | 默认首选,O(1) |
LinkedHashMap |
继承 HashMap,再串一条双向链表 |
允许 | 插入顺序或访问顺序(LRU) | 适合做缓存 |
TreeMap |
红黑树 | 不可 | 键自然顺序或自定义 Comparator |
O(log n),支持区间查询 |
| 实现类 | 同步方式 | Key 可为 null | 并发度 | 备注 |
|---|---|---|---|---|
Hashtable |
全表锁 | 不可 | 低 | 上古类,别用 |
Collections.synchronizedMap(new HashMap<>()) |
包装后全表锁 | 不可 | 低 | 简单兼容旧代码 |
ConcurrentHashMap |
分段锁(JDK7)→桶级锁 / 无锁(JDK8+) | 不可 | 高 | 读写并行,默认首选 |
| 实现类 | 特点 |
|---|---|
WeakHashMap |
键是弱引用,GC 自动清理,适合做“键生命周期随对象”的缓存 |
IdentityHashMap |
用 == 比较键,而不是 equals,用于图算法、对象拓扑复制 |
EnumMap |
键必须是同一 enum 类型,内部用数组,比 HashMap 快且内存省 |
tldr 版:
- 单线程 / 常规:默认
HashMap - 需要插入 / 访问顺序:
LinkedHashMap - 需要排序 / 区间
: TreeMap(单线程)或ConcurrentSkipListMap(并发) - 并发:首选
ConcurrentHashMap;别再new Hashtable()
Generic⚓︎
关于泛型(generic):
- 泛型提供了一种向编译器传递容器类型信息的方式,以便进行类型检查
- 除了枚举、匿名内部类和
Exception类之外,所有类型都可以拥有泛型参数
泛型类(generic class) 必须指定两种类型:集合本身的类型(此处为 ArrayListString
将类型作为参数:
T是占位符,生成对象时传具体类型- 实际上 Java 常用占位符为
E而非T(E代表 element)
多类型参数:类型参数数量不限制,按位置对应
接口可能也会用到泛型类型:
interface Codec<T> {
T decode(String s);
}
enum IntCodec implements Codec<Integer> {
INSTANCE;
public Integer decode(String s) {
return Integer.valueOf(s);
}
}
定义一个简单的泛型类:
public interface List<E> {
void add(E x);
Iterator<E> iterator();
}
public interface Iterator<E> {
E next();
boolean hasNext();
}
泛型类里的静态方法:
- 方法前写
<T>,编译器帮你推
public static <T> List<T> asList(T... a) {
return Arrays.asList(a);
}
// 类型推断
List<String> names = asList("A", "B");
例子
public final class Box<T> {
private T value;
public Box(T value) { this.value = value; }
public T get() { return value; }
public void set(T value){ this.value = value;}
// 静态泛型工厂,方便创建
public static <E> Box<E> of(E value) { return new Box<>(value); }
public static void main(String[] args) {
Box<String> sBox = Box.of("Hello");
System.out.println(sBox.get()); // Hello
Box<Integer> iBox = new Box<>(42);
iBox.set(iBox.get() + 1);
System.out.println(iBox.get()); // 43
}
}
Java 的泛型方式:
- 代码没有多个副本
- 泛型类型声明一次性编译,并转换为一个单独的类文件
- 泛型声明有形式类型参数
- 为形式类型参数使用简洁(如果可能的话,单字符)且富有启发性的名称
泛型与子类型 (subtyping):如果 Foo 是 Bar 的一个子类型(子类或子接口G 是某种泛型类型声明,那么 G<Foo> 并不是 G<Bar> 的子类型。
List<String> ls = new ArrayList<String>();
List<Object> lo = ls;
lo.add(new Object());
String s = ls.get(0);
通配符(wildcard):
void printCollection(Collection<?> c) {
for (Object e : c) {
System.out.println(e);
}
}
Collection<?> c = new ArrayList<String>();
c.add(new Object());
例子
以下代码实现 Shape 类及其子类:
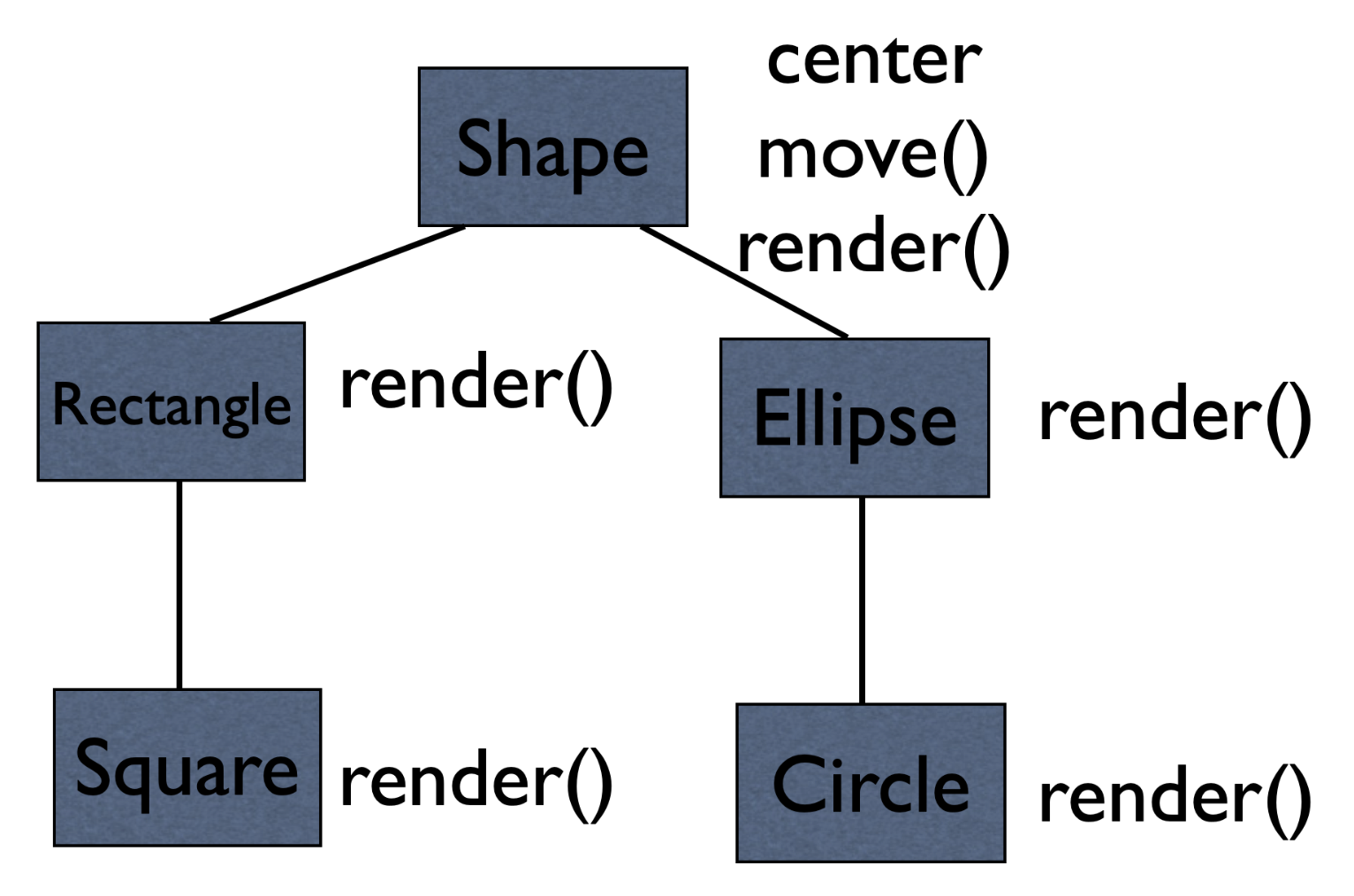
public abstract class Shape {
public abstract void draw(Canvas c);
}
public class Circle extends Shape {
private int x, y, radius;
public void draw(Canvas c) { ... }
}
public class Rectangle extends Shape {
private int x, y, width, height;
public void draw(Canvas c) { ... }
}
// To draw them on a canvas
public void draw(Shape s) {
s.draw(this);
}
public void drawAll(List<Shape> shapes) {
for (Shape s: shapes) {
s.draw(this);
}
}
// Bounded wildcards
public void drawAll(List<? extends Shape> shapes) { ...}
double sum(List<? extends Number> nums) { /* 只读 */ }
void fill(List<? super Integer> ints) { /* 只写 */ }
extends v.s. super
extends 只能 " 读 ",super 只能 " 写”(相对变量而言)
| 界限 | 英文含义 | 能放什么 | 能拿什么 | 典型场景 |
|---|---|---|---|---|
? extends Integer |
上界通配符 | 什么也不能放(除 null) | 只能读出 Integer 或其子类 |
消费数据,如求和 |
? super Integer |
下界通配符 | 可以写 Integer 及其子类 |
只能拿出 Object(丧失具体类型) |
生产数据,如填充 |
运行时擦除:
- 泛型只存在于编译期
- 编译后擦除到
Object或通配上限
例子
对于:
OpenJDK 24 的 javap -p -v ( 或 -c -v )为了可读性 ,把擦除后的Object / Number又显示成原泛型符号 T,但 Signature 属性 Object 和字节码指令里仍然是 Object。
泛型不能做的事:
new T():擦除后无构造T.class:无具体类型信息List<int>:基本类型不能用
Stream⚓︎
例子
惰性方式 (lazy way):
artists.stream()
.filter(artist -> {
System.out.println("Checking artist: " + artist.getName());
return artist.isFrom("London");
})
.forEach(artist -> System.out.println("Artist from London: " + artist.getName()));
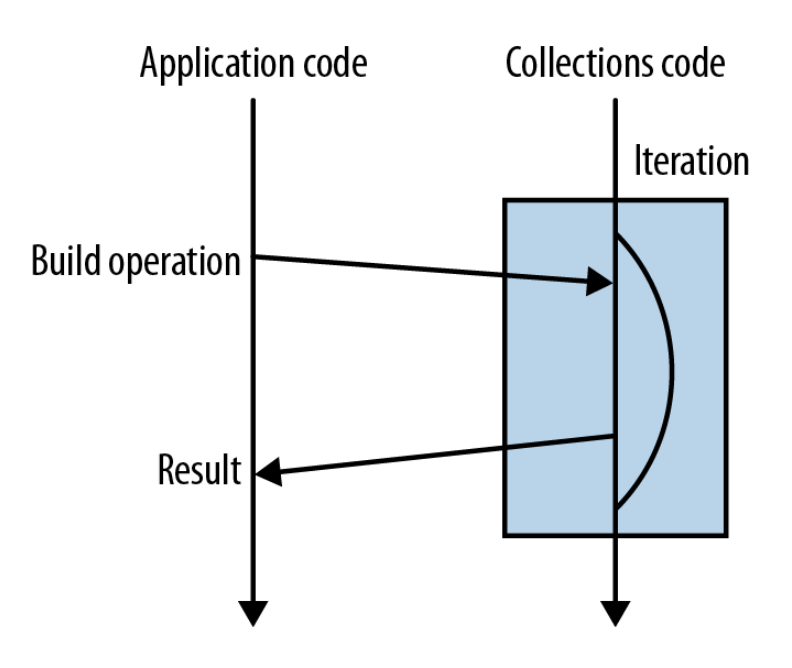
惰性方式 v.s. 积极方式
-
filter()返回Stream--> 惰性方式- 中间操作(intermediate operations),它们只是构建流水线,不会立即执行
-
count()返回int--> 积极方式- 终端操作(terminal operations) 会触发流的计算,并产生最终结果
-
一次流计算可以有很多个中间操作,但只能有一个终端操作
流的原语 (primitives):
- 在
java.util.stream包里,JDK 提供了 4 套专门用于基本类型的流类型,每套都带独立的静态工厂和专用中间 / 终端操作 - 它们全部实现
BaseStream接口,与Stream并列,互不继承
| 流类型 | 元素类型 | Lambda 类型 | 专用终端例 |
|---|---|---|---|
IntStream |
int |
int |
sum(),average(),summaryStatistics() |
LongStream |
long |
long |
同上 |
DoubleStream |
double |
double |
同上 |
- 没有
FloatStream/CharStream/BooleanStreamfloat被提升为double,char/boolean用IntStream装
流的引用:Stream<T>,任意引用类型 T
Creating Stream⚓︎
-
来自
Collection来源 方法 流类型 java.util.Collection.stream(),.parallelStream()Stream<T>java.util.Map.entrySet().stream()...Stream<Map.Entry<K,V>> -
来自数组
来源 方法 流类型 任意引用类型数组 Arrays.stream(T[])Stream<T>基本类型数组 Arrays.stream(int[])...IntStream / LongStream / DoubleStream指定区间 Arrays.stream(array, start, end)同上 -
静态工厂方法
类 方法 StreamStream.of(T…),Stream.ofNullable(T)StreamStream.empty()StreamStream.generate(Supplier<T>)StreamStream.iterate(T, UnaryOperator<T>)StreamStream.iterate(T, Predicate<T>, UnaryOperator<T>)(1.9+ 带终止条件)IntStream, LongStream, DoubleStreamIntStream.of(int…),IntStream.range(1, 10),IntStream.rangeClosed(1, 10) -
Stream还可以从缓冲字符流(BufferedReader) 、文件、正则表达式、随机数发生器、Optional和并行工具产生
Common Lazy Operations⚓︎
-
map方法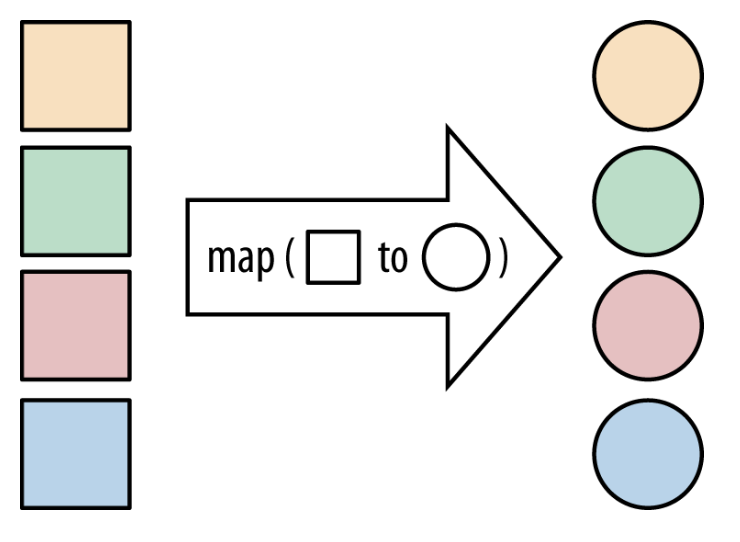
-
filter方法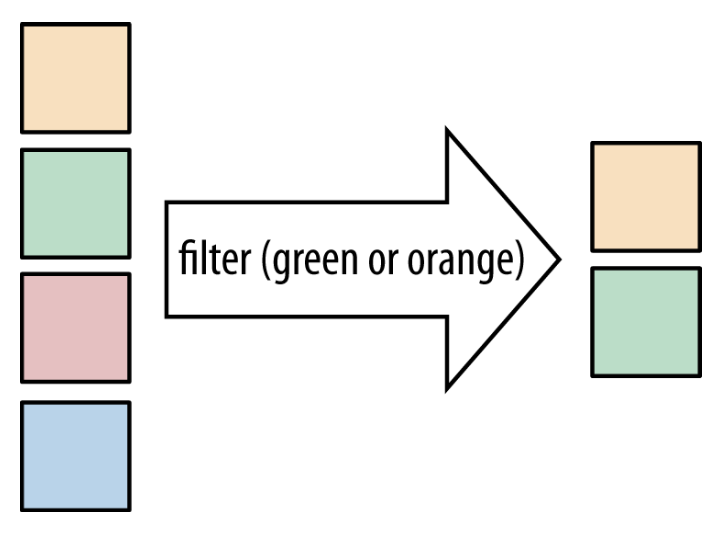
-
flatMap方法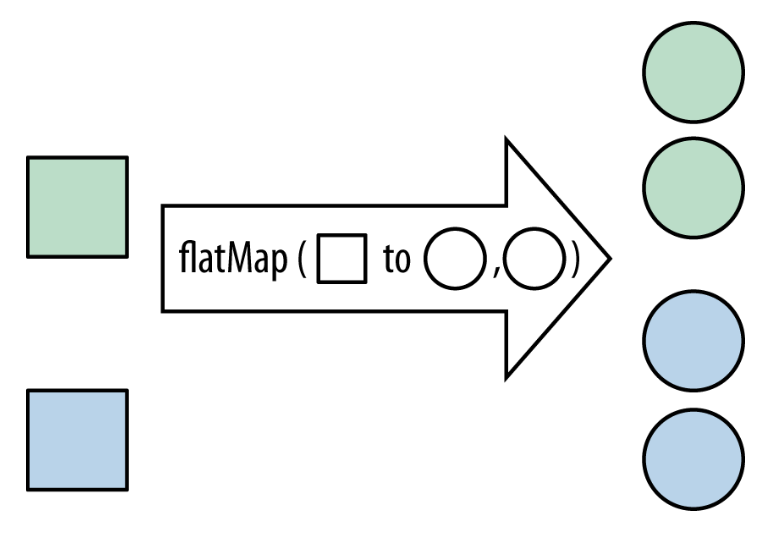
Common Eager Operations⚓︎
-
迭代
方法名 返回类型 说明 forEach(Consumer)void遍历每个元素 forEachOrdered(Consumer)void顺序遍历(适用于并行流) 例子
List<String> list = List.of("java", "python", "go"); list.stream() // 拿到流 .forEach(System.out::println); // 终端操作:逐行打印 AtomicInteger sum = new AtomicInteger(0); IntStream.rangeClosed(1, 5) // 1 2 3 4 5 .forEach(sum::addAndGet); // 累加 System.out.println(sum.get()); // 15 List.of("a", "b", "c", "d") .parallelStream() .forEachOrdered(System.out::print); // 保证按原顺序打印 -
收集
方法名 返回类型 说明 toArray()Object[]转为数组 toArray(IntFunction<A[]>)A[]转为指定类型数组 collect(Collector)R收集元素到集合或其他结构 -
归约:对于一个值集合,生成单一结果
方法名 返回类型 说明 reduce(...)Optional<T>或T归约操作 min(Comparator)Optional<T>最小值 max(Comparator)Optional<T>最大值 count()long元素个数 例子
```java int count = Stream.of(1, 2, 3).reduce(0, (acc, element) -> acc + element); ``` <div style="text-align: center"> <img src="images/lec4/11.png" width=30%> </div> -
短路 (short-circuiting)
方法名 返回类型 说明 anyMatch(Predicate<T>)boolean一旦找到匹配元素,立即返回 trueallMatch(Predicate<T>)boolean一旦遇到不满足的元素,立即返回 falsenoneMatch(Predicate<T>)boolean一旦遇到满足的元素,立即返回 falsefindFirst()Optional<T>返回第一个元素,找到即停 findAny()Optional<T>返回任意一个元素(并行流中可能更快) 例子
// 打印素数个数 System.out.println(IntStream.range(2, x) .filter(i-> { System.out.println("Testing " + i); return x % i == 0;}) .count()); // 打印第一个素数 System.out.println(IntStream.range(2, x) .filter(i-> { System.out.println("Testing " + i); return x % i == 0;}) .findFirst()); // 并行流 System.out.println(IntStream.range(2, x) .parallel() .filter(i-> { System.out.println("Testing " + i); return x % i == 0;}) .findAny());
Parallel Stream⚓︎
parallelStream() 把“串行流”换成“并行流”,底层开启多线程,对数据进行分片 -> 并行处理 -> 结果合并。
例子
何时使用并行流?
- 数据量小;线程切换开销:计算收益,可能更慢
- 数据量大 + 计算重:明显加速
- 需要顺序:并行后顺序混乱,需要
forEachOrdered或sorted等额外操作 - 有状态 / 锁:容易出现竞态、性能骤降
陷阱
性能改善?
long t1 = System.nanoTime();
long a = LongStream.rangeClosed(1, 10_000_000).sum(); // 串行
long t2 = System.nanoTime();
long b = LongStream.rangeClosed(1, 10_000_000).parallel().sum(); // 并行
long t3 = System.nanoTime();
System.out.printf("串行: %d ms,并行: %d ms%n", (t2 - t1) / 10_000_000, (t3 - t2) / 10_000_000);
评论区